
At the core of the microservices architecture is the concept of dividing applications into smaller, independent components. Each microservice handles a specific functionality and operates autonomously. These services are small applications themselves and can be developed, deployed, operated, and scaled independently.
The microservices approach can provide numerous benefits to software development organizations and is particularly effective in scenarios where business requirements are highly dynamic and rapidly evolving. However, it also brings its own challenges.
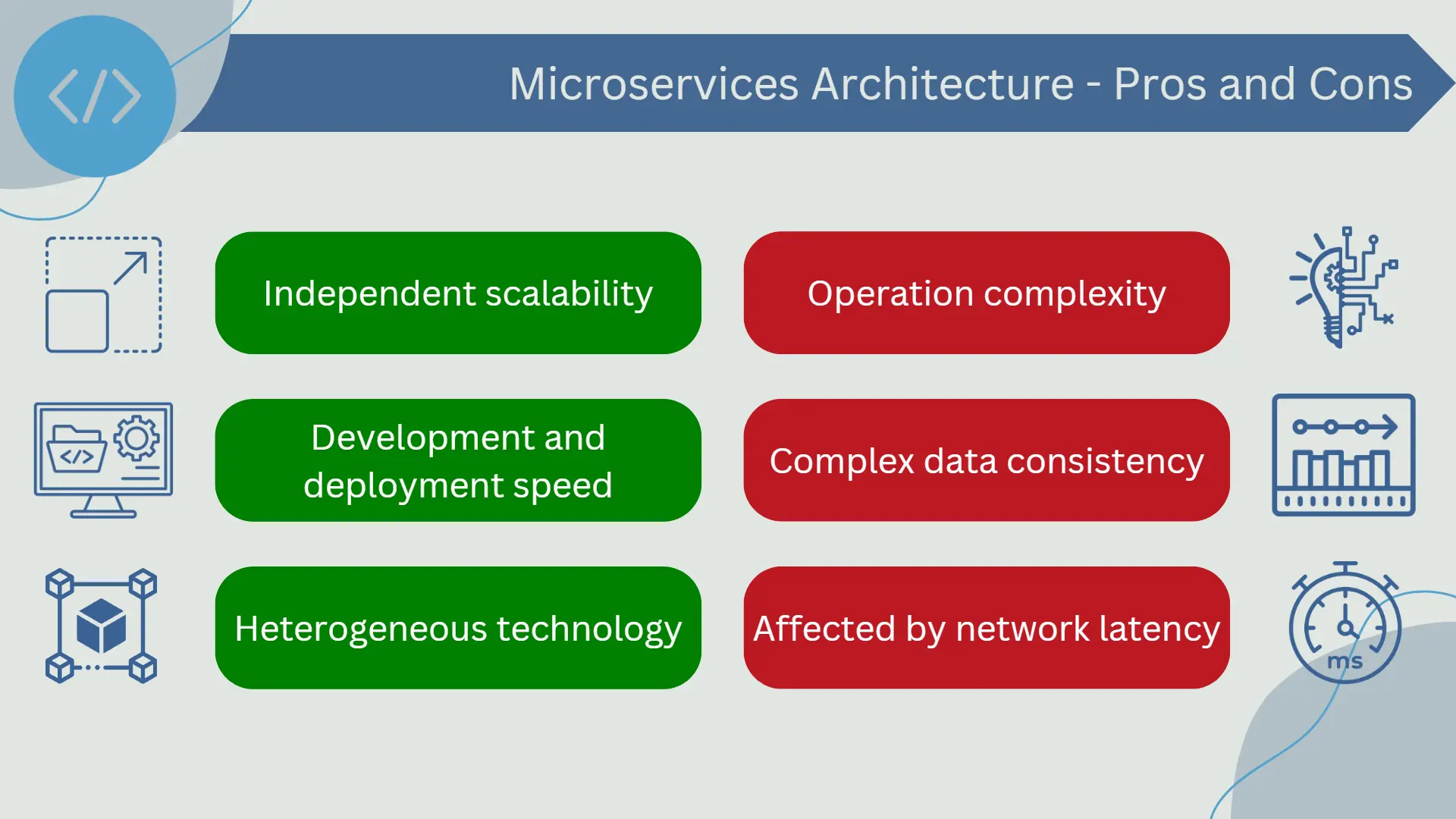
Some advantages of using microservices include:
- Independent scalability: Each service can scale independently based on its specific demand. This can lead to more efficient resource utilization and better ability to handle load spikes.
- Faster development and deployment: Since services are independent of each other, teams can develop, test, and deploy each service independently and in parallel. This can result in faster development and deployment speed.
- Heterogeneous technology: Each microservice can be developed using the most suitable technology for its specific functionality. This means you could have a microservice written in Java, another in Python, and another in Node.js, all working together in the same application.
Despite these advantages, there are some disadvantages to consider when opting for this type of architecture:
- Operational complexity: Managing numerous independent services can be complex. You need tools and processes to handle deployment, monitoring, communication between services, error handling, and scalability of each individual service.
- Data consistency: Maintaining data consistency across multiple services can be challenging as each microservice has its own database.
- Network latency: Since microservices often communicate with each other over the network, latency can be a concern. Requests that require communication between multiple services may be slower than in a monolithic architecture.
Microservices structure
The microservices architecture divides an application into a collection of smaller, independent services that are organized around specific business functionalities. Each of these services can be developed, deployed, and scaled independently, providing great flexibility in managing the application.
- Codebase: Each microservice has its own codebase, which can be written in any programming language that is most suitable for the specific functionality of the service. This means that different microservices within the same application can be written in different languages.
- Database: Each microservice has its own database, allowing each service to manage its own data model. This isolates the services from each other, ensuring that a problem in one service does not affect the others. However, this segregation can also complicate operations that require transactions or queries across multiple services.
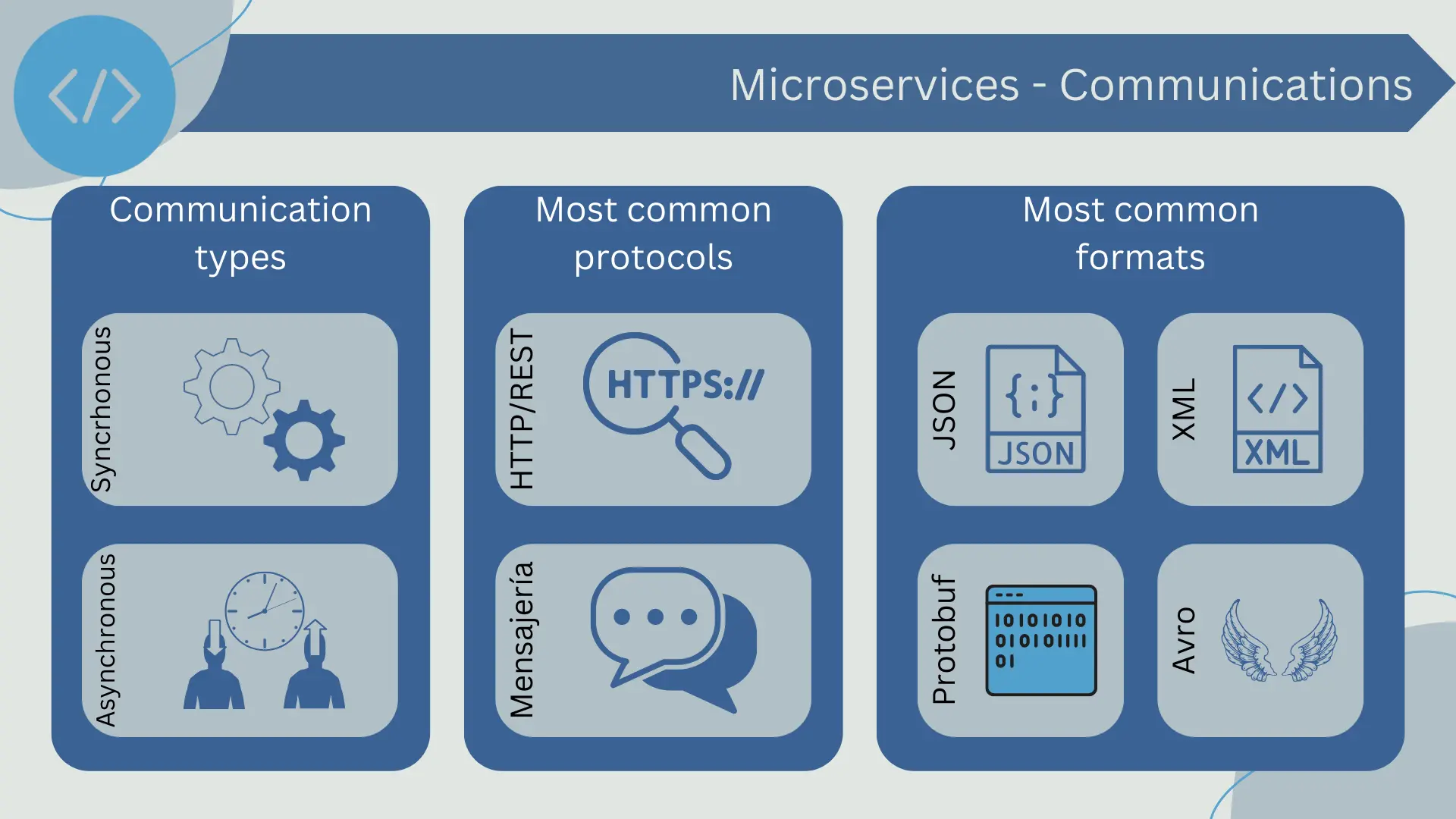
- Communication between Services: Microservices communicate with each other using lightweight network protocols, typically HTTP/REST or gRPC, and use data interchange formats such as JSON or Protocol Buffers. Client requests typically arrive through an API interface, which then routes the requests to the corresponding services. Communication between microservices can be synchronous or asynchronous. In synchronous communication, a service waits for a response from another service before proceeding. In asynchronous communication, a service sends a message to another service and then continues its processing without waiting for a response.
- Service Discovery: In a microservices architecture, there can be dozens or even hundreds of different services. To manage this complexity, many microservice systems use a service discovery mechanism that allows services to find and communicate with each other. The service discovery service maintains a real-time registry of all services in the system and their current status.
Codebases
Each microservice in a microservices architecture is independent and encapsulates a specific functionality. This independence extends to the codebase of each service.
The codebase of a microservice is the set of source code that defines its functionality. In microservices architectures, each service has its own separate codebase. This means that each microservice can be developed, tested, and deployed independently of the others. This independence can lead to increased productivity and efficiency as development teams can work in parallel and make changes to their respective services without affecting others.
Furthermore, each microservice can be developed using the programming language that is most suitable for its specific functionality. This means that you are not limited to a single programming language for the entire application. For example, you could have an image processing microservice written in Python (which has excellent libraries for image processing), while another service handling business logic could be written in Java or C#.
However, this diversity can also present challenges. Managing a project with multiple programming languages can be more difficult, and development teams need to be equipped with a wide range of skills to maintain and enhance each service. Therefore, despite the flexibility that this independence can provide, it is crucial to maintain certain consistent coding standards and practices across all services to ensure code maintainability and consistency.
Databases
In a microservices architecture, each service has its own independent database. This is known as the "database per service" principle. This approach helps ensure that each service is as decoupled as possible from the others, which in turn facilitates independent development, deployment, and scaling of each service.
Having separate databases for each microservice has several advantages. The first is that it reduces coupling between services. If one service fails or goes down, the data of other services is not affected. Secondly, each service can use the type of database that best suits its needs. For example, a service handling complex relationships between entities could use a relational database, while another service handling large volumes of time series data could use a purpose-optimized NoSQL database.
However, this approach also has its challenges. The first is managing consistency between services. As each microservice has its own database, maintaining consistency across different services can be complex, especially in operations that span multiple services.
Additionally, performing queries across multiple services can be more complex than in a monolithic architecture. In a monolithic application, you could make a single database query to retrieve all the data you need. But in a microservices architecture, this data may be scattered across multiple databases, and you may need to make multiple calls to different services to gather all the data you require.
Lastly, this approach can increase the complexity of database operations. You will need tools and processes to manage multiple databases, each possibly using different technologies. Additionally, backup and restoration operations may become more complex, and you may need to coordinate these operations across all your services.
Service Communication
Service communication is fundamental in a microservices-based architecture. Since microservices are autonomous and handle different functionalities, they need to interact with each other to complete application operations.
The most common forms of communication between microservices are HTTP/REST requests and the use of Messaging protocols, although other techniques such as gRPC or GraphQL can also be used.
- HTTP/REST: It is a common form of communication between microservices due to its simplicity and universality. In this model, one microservice makes an HTTP request to another microservice, which responds with the requested data or a confirmation that the requested action has been performed.
- Messaging: Using a messaging system is another common way of communication between microservices. In this case, microservices publish and consume messages from a messaging bus, which can be a message queue system, a data streaming system, or similar. This allows for asynchronous communication and can help further decouple microservices.
The communication between microservices can be synchronous or asynchronous. In synchronous communication, a service waits for a response from another service before proceeding. In asynchronous communication, a service sends a message to another service and then continues its processing without waiting for a response. Both have their pros and cons, and the choice depends on the specific needs of the application.
It is also necessary at this point to mention the data format, which defines how the information sent between services is structured. The two most common formats used in microservices architectures are JSON and XML, although other formats such as Protocol Buffers or Avro can also be used depending on the specific needs of the system.
- JSON (JavaScript Object Notation): It is a lightweight and human-readable data format. It is widely used in web applications and is the default data format for many RESTful APIs. JSON is particularly useful in a microservices architecture due to its simplicity and versatility.
- XML (eXtensible Markup Language): It is another data format commonly used in service communication. Although it is more verbose than JSON, XML is extremely flexible and allows for a more detailed description of data. This can be beneficial in systems where data is complex or where a high degree of interoperability is required.
- Protocol Buffers (also known as Protobuf): They are a binary data format developed by Google. They are more efficient in terms of size and processing speed compared to JSON or XML, but they are less human-readable. Protocol Buffers can be a good choice in systems where performance is a major concern.
- Avro: It is a binary data format that also supports schema definition. It was developed in the context of the Apache Hadoop project for use in distributed big data systems. Avro is useful in systems where data needs to be persisted or sent over the network with high efficiency.
It is important to remember that the chosen data format should be suitable for the specific needs of your system. Each format has its own advantages and disadvantages, and the choice between them will depend on factors such as the complexity of your data, the performance requirements of your system, and the technologies you are using.
Service Discovery
In a microservices architecture, there are often a large number of services that need to communicate with each other. However, due to the dynamic and scalable nature of this architecture, services can change, scale, and move frequently. This is where service discovery becomes critical.
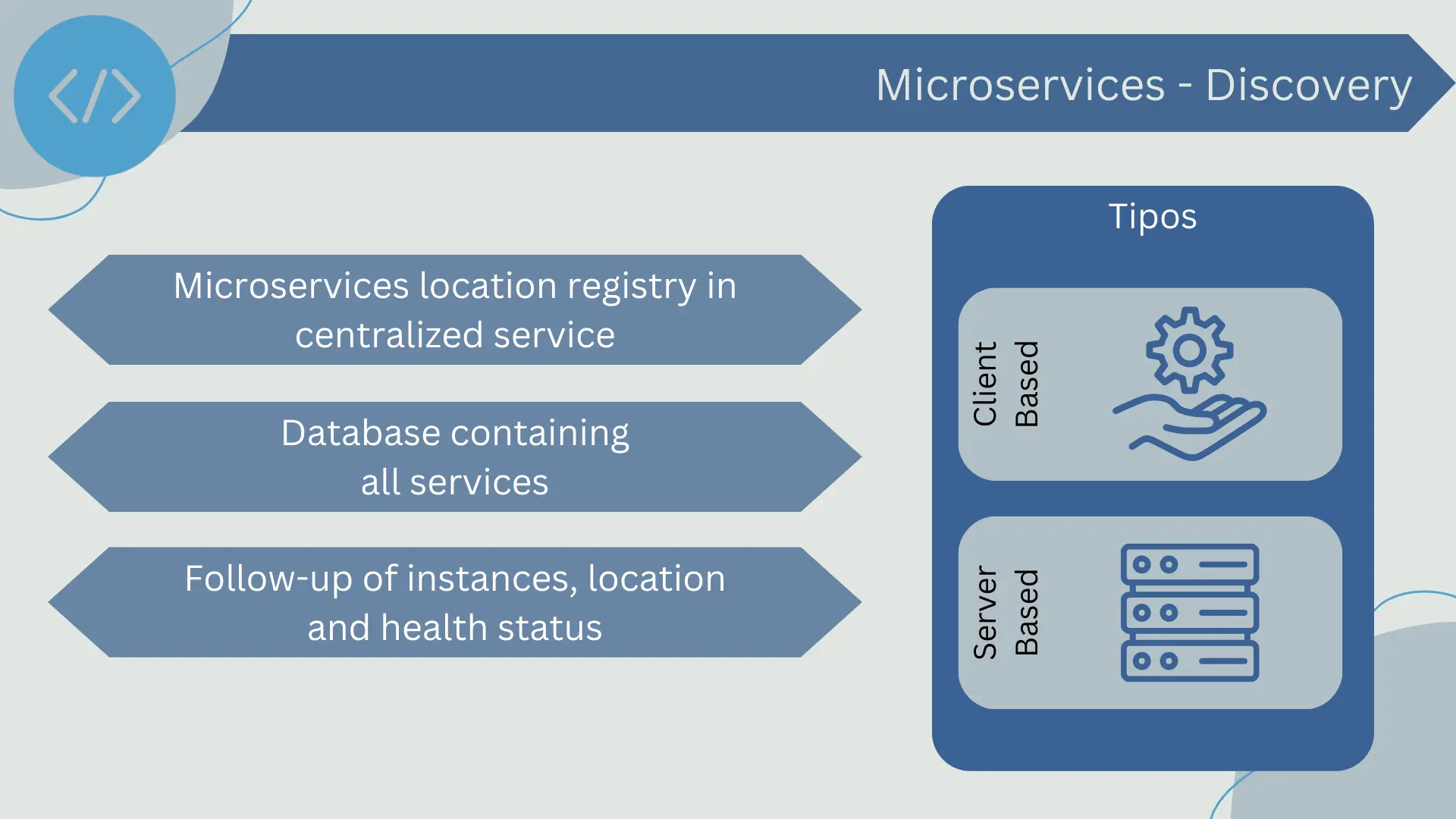
Service discovery is a pattern in which microservices can register their location in a centralized service registry and can also find and discover other services using this registry.
The service registry acts as a database or directory of all the services available in the microservices architecture, keeping track of service instances, their location, and their health status. When a new microservice is deployed, it registers in this registry providing all the necessary information. If a service goes down or is removed, it is also updated in the registry. If a service fails regular health checks, it is marked as unavailable in the registry.
There are two main approaches to service discovery: client-based discovery and server-based discovery.
- In client-based discovery, the service clients themselves are responsible for determining the locations of services and load balancing. To do so, they query the service registry, select a service, and then make the request.
- In server-based discovery, the client makes the request through a router, which is an intermediate component between the client and services. The router queries the service registry and uses load balancing to route the request to the appropriate service.
Efficient implementation of service discovery can be challenging due to the need to maintain registry consistency, the need for fast and efficient service discovery, and the need to handle service availability changes and failures. However, its role is crucial in maintaining an efficient and flexible microservices architecture.
Request handling
Request handling in a microservices architecture is a crucial aspect that requires careful consideration. Due to the distributed nature of microservices, a single client request may involve multiple requests between various services. The following are some important concepts related to request handling in microservices.
Orchestration and Choreography
Orchestration and choreography are two approaches to coordinate interactions between microservices. Both have their own advantages and disadvantages, and the choice between them often depends on the specific problem being solved.
In practice, many microservices architectures use a combination of orchestration and choreography. Some workflows may be better managed by an orchestrator, while others may benefit from the more decentralized nature of choreography. The key is to understand the benefits and limitations of each approach and apply the most suitable one for each situation.
Orchestration
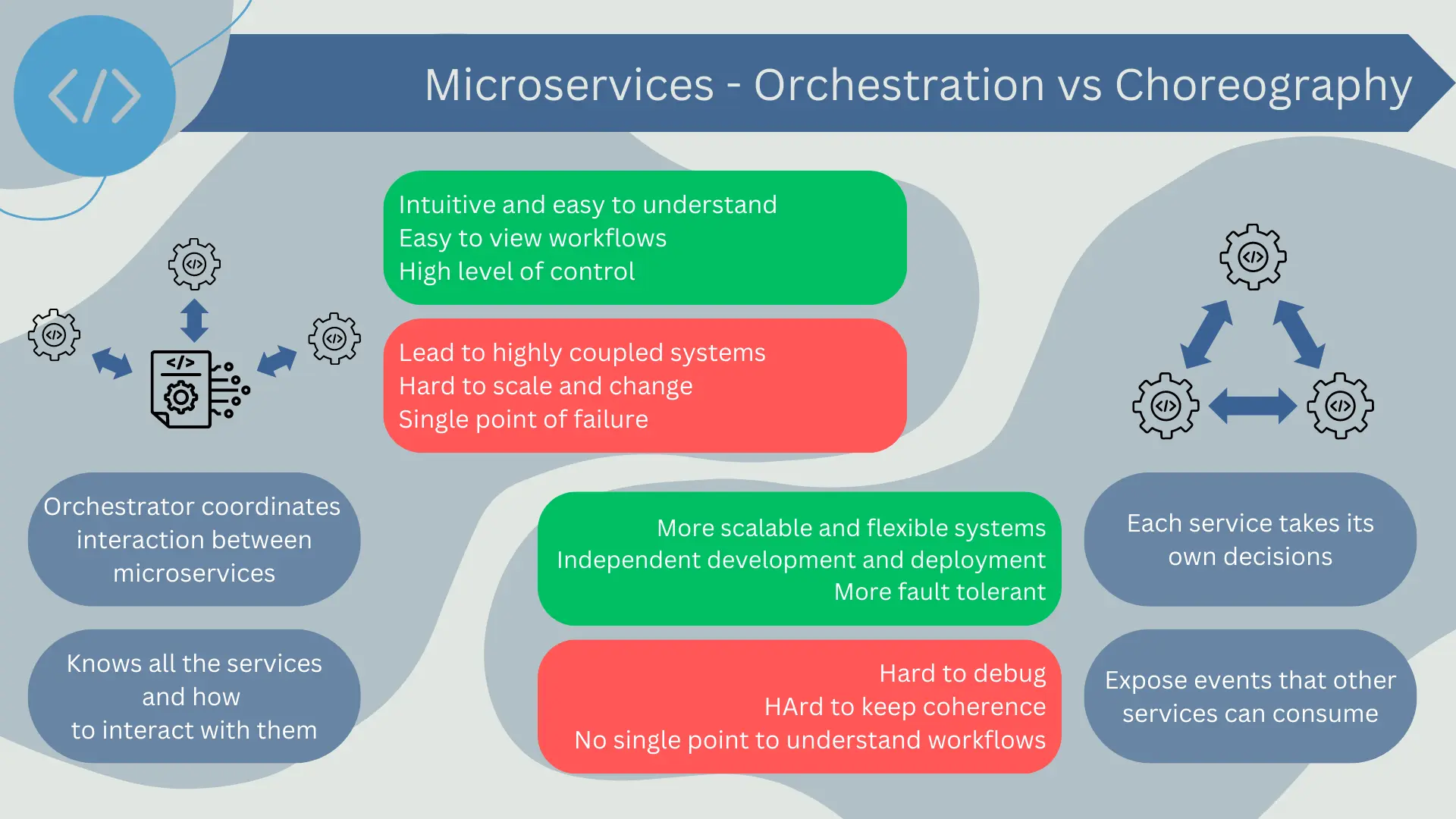
Orchestration is a pattern where a component, known as the orchestrator, coordinates all interactions between services. The orchestrator is aware of all services in the architecture and knows how to interact with each of them to fulfill a certain task or workflow.
The advantage of orchestration is that it is quite intuitive and easy to understand. Workflows can be easily visualized and reasoned about because everything is managed from a single place. It also allows for a high level of control, as the orchestrator can handle requests and responses very precisely.
However, orchestration can lead to highly coupled systems since the orchestrator needs to have detailed knowledge of each service it interacts with. This can make the system more difficult to change and scale. Additionally, the orchestrator can become a single point of failure if not designed properly.
Choreography
Choreography is a pattern where each service acts autonomously and makes its own decisions. Instead of being directed by a central orchestrator, services publish events that other services can choose to listen to and react upon.
Choreography can lead to more scalable and flexible systems, as each service can be developed and deployed independently without the need to coordinate with a central orchestrator. It can also make the system more resilient to failures, as there is no single point of failure.
However, choreography can be more difficult to understand and reason about, as there is no single place to see all the workflow logic. This can make debugging and error handling more challenging. It can also be harder to ensure consistency, as each service can act independently.
API Gateway
An API Gateway is an interface that exposes an API for interaction between clients and services in a microservices architecture. This component centralizes the handling of some common and necessary functions to maintain the integrity and performance of the architecture.
Here are some key aspects of the API Gateway:
- Single entry point: In a microservices architecture, a client may need to interact with multiple services to complete a single operation. Instead of requiring the client to make requests to each service individually, the API Gateway provides a single entry point that routes requests to the appropriate services.
- Request handling: The API Gateway can handle tasks related to requests, such as authentication, authorization, load balancing, rate limiting, and request routing. This allows microservices to focus on their specific tasks without worrying about these aspects.
- Request and response transformation: In some cases, the data entering or leaving the services may need to be transformed to be more useful or consistent. For example, a service may return data in a format that is not optimal for the client. The API Gateway can perform these transformations.
- Service discovery: In a microservices architecture, services can be deployed, updated, and scaled dynamically. The API Gateway can work with a service registry to track the location and status of services in the system.
- Failure and latency handling: An API Gateway can also help handle failures and latency in the microservices architecture. For example, it can implement resilience patterns like the Circuit Breaker to handle failures in services.
In summary, an API Gateway plays a crucial role in a microservices architecture by handling various cross-cutting concerns, allowing services to focus on their specific business logic. However, it is also a critical piece of infrastructure that needs to be carefully designed and maintained, as any failure in the API Gateway could have a significant impact on the entire system.
Resilience Patterns
Resilience patterns are strategies to help a system deal with failures and recover from them. In a microservices architecture, these patterns are particularly important due to the distributed nature of the system. Here are some common resilience patterns in microservices.
- Timeouts: This pattern limits the time a service can wait for a response. If the response is not received within the specified time, the request is considered failed. Timeouts are essential to prevent a service from being blocked while waiting for a response from a failing or overloaded service.
- Retries: This pattern involves automatically retrying a failed request. This can be useful for handling transient errors, such as a flaky network. However, retries should be used carefully to avoid further overloading a service that is already failing.
- Circuit Breaker: It allows a service to stop making requests to another service if it is detected that the latter is failing. After a predefined time, a "test" request is allowed to see if the service has become available again. If the test request succeeds, the circuit closes and requests can continue; if it fails, the circuit remains open for another period of time.
- Bulkheads: It involves isolating failures in one part of the system to prevent them from spreading to other parts. This pattern takes its name from the watertight compartments (bulkheads) of a ship, which can be sealed to prevent water from flowing from one compartment to another.
- Backpressure: It is used to handle overload. When a service can't handle more requests, it can use backpressure to signal clients or other services to reduce the rate of requests.
These resilience patterns can help maintain the availability and reliability of a microservices system even when failures occur. However, it's also important to remember that resilience patterns are not a one-size-fits-all solution; they should be combined with other practices such as monitoring and error handling to create truly resilient systems.
Scalability
One of the main benefits of a microservices architecture is its scalability. Microservices can be individually scaled according to demand, allowing the architecture to adapt to different workloads more efficiently and effectively compared to monolithic architectures. The following describes some key aspects of scalability in microservices.
Horizontal and Vertical Scalability
Scalability in a microservices architecture can be horizontal or vertical, and both are fundamental strategies for handling variable demands on system resources. Additionally, they are complementary strategies. The choice of when and how to scale depends on the specific characteristics and requirements of each service.
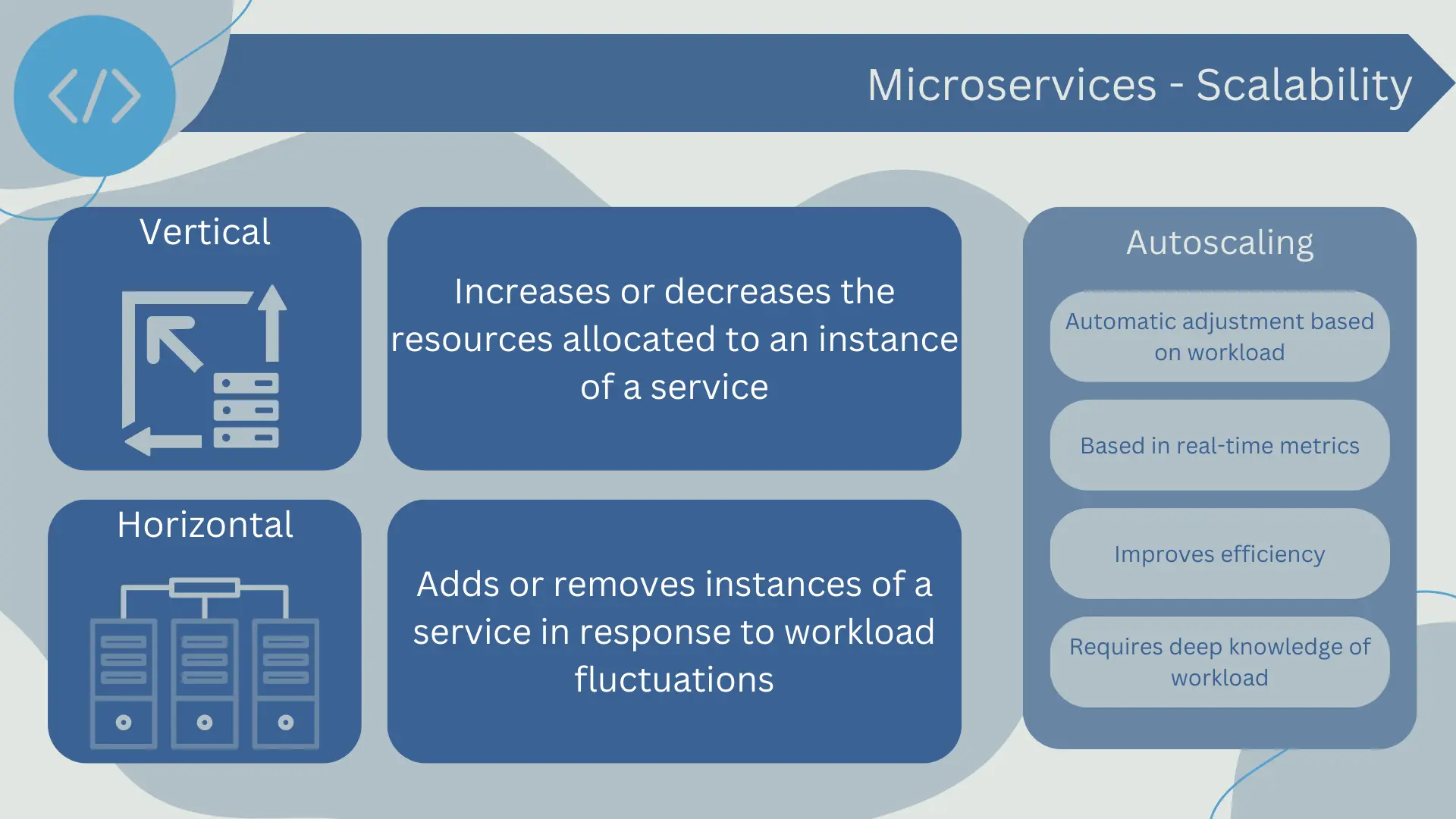
Horizontal Scalability
Horizontal scalability, also known as scaling out/in, refers to adding or removing instances of a service in response to workload fluctuations. This is particularly beneficial in a microservices architecture, as each service can scale independently of others, allowing for greater control and efficiency.
For example, if an e-commerce service experiences a surge in demand during a flash sale, only the services related to order handling and payments may need to be horizontally scaled to handle the increased traffic, while other services like product reviews may remain unchanged.
Horizontal scaling is effective in improving availability and fault tolerance since even if one instance fails, the other instances of the same service can continue handling requests. However, it can also introduce complexity in managing data and state, instance synchronization, and the need for effective load balancing.
Vertical Scalability
Vertical scalability, also known as scaling up/down, refers to increasing or decreasing the resources allocated to an instance of a service, such as memory, CPU, or storage. This can be useful for handling resource-intensive workloads that don't benefit from parallel execution across multiple instances.
For example, a data analysis service may need to be vertically scaled to efficiently process large datasets. However, vertical scaling has physical limitations and can be costly, as it involves adding more powerful hardware or acquiring larger instances in a cloud platform. Additionally, it doesn't improve availability or fault tolerance in the same way horizontal scaling does.
Autoscaling
Autoscaling is an essential feature for maintaining efficiency and performance in a microservices architecture. This capability allows the system to automatically adjust the number of instances or the power of a service based on the current workload demands.
Autoscaling is typically based on real-time metrics such as CPU usage, memory, requests per second, or even business metrics to determine when and how to scale. For example, if the CPU usage of a service exceeds a predefined threshold, the system could automatically initiate new instances of that service to handle the additional load.
There are two main forms of autoscaling: automatic horizontal scaling and automatic vertical scaling. Automatic horizontal scaling adjusts the number of instances of a service, while automatic vertical scaling adjusts the resources allocated to an instance, such as CPU and memory.
Autoscaling has several benefits:
- Resource efficiency: Autoscaling can help utilize resources more efficiently by allowing the system to adapt to real-time workload demands.
- Improved performance: By adjusting the number of instances or resources allocated to a service, autoscaling can help maintain system performance even during peak loads.
- Cost savings: In cloud environments, autoscaling can reduce costs by ensuring that only necessary resources are used and paid for.
- Resilience: Autoscaling can improve system resilience by allowing the system to handle failures and disruptions more effectively.
However, implementing autoscaling can be challenging as it requires a deep understanding of workload characteristics and system capabilities. It is also important to note that autoscaling may not be the right solution for all situations and may be more effective when combined with other load and resource management techniques.
Load Balancing
Load balancing is an essential strategy in a microservices architecture to efficiently distribute network requests across a set of servers or service instances, thereby maximizing performance and minimizing response time. In the context of microservices, load balancing is crucial for scalability and availability of services.
Here are some key points about load balancing in microservices:
- Request distribution: A load balancer accepts incoming requests and distributes them among multiple service instances, ensuring that no instance is overloaded. This can be done using a variety of algorithms, such as round-robin, where requests are sequentially distributed to each server in order, or least connections, where requests are sent to the server with the fewest active connections.
- High availability and fault tolerance: By distributing requests among multiple instances, load balancing helps ensure that if one instance fails, requests can be redirected to other active instances. This is crucial for maintaining the availability and reliability of services in a microservices architecture.
- Scalability: Load balancing is fundamental to supporting horizontal scalability in microservices. As more instances of a service are added to handle increased workload, the load balancer can effectively distribute requests among all available instances.
- Service discovery: In many cases, load balancers also work in conjunction with service discovery systems, which maintain a registry of available service instances. This allows the load balancer to know the location and status of each service instance.
It is important to note that load balancing can introduce its own challenges, such as the need to maintain data consistency between instances and handle "session affinity" for requests that need to be handled by the same instance. Additionally, the load balancer itself can become a single point of failure if not implemented with high availability.
Statelessness Design
Statelessness design is a fundamental principle in microservices architecture. In a stateless service, each request is independent and does not rely on any prior or future information. This means that the service does not need to remember information from the previous request to process the next one.
Statelessness design has several benefits in microservices architecture:
- Scalability: Stateless services are easier to scale horizontally since any instance of a service can handle any request. They don't need to share or synchronize state, making the addition of new instances a straightforward process.
- Resilience: Stateless services are more resilient to failures since there is no state that can be lost if an instance fails. If one instance goes down, another can easily take over its workload.
- Simplicity: Stateless services are simpler to understand and maintain. They don't have to deal with the complexity of state synchronization or handling race conditions.
However, there are situations where maintaining some state may be unavoidable, such as user sessions or multi-step transactions. In these cases, a variety of strategies can be used to handle state, such as storing state in a database or using a session server. However, these solutions can introduce their own complexity and challenges and should be handled carefully.
Development and Lifecycle
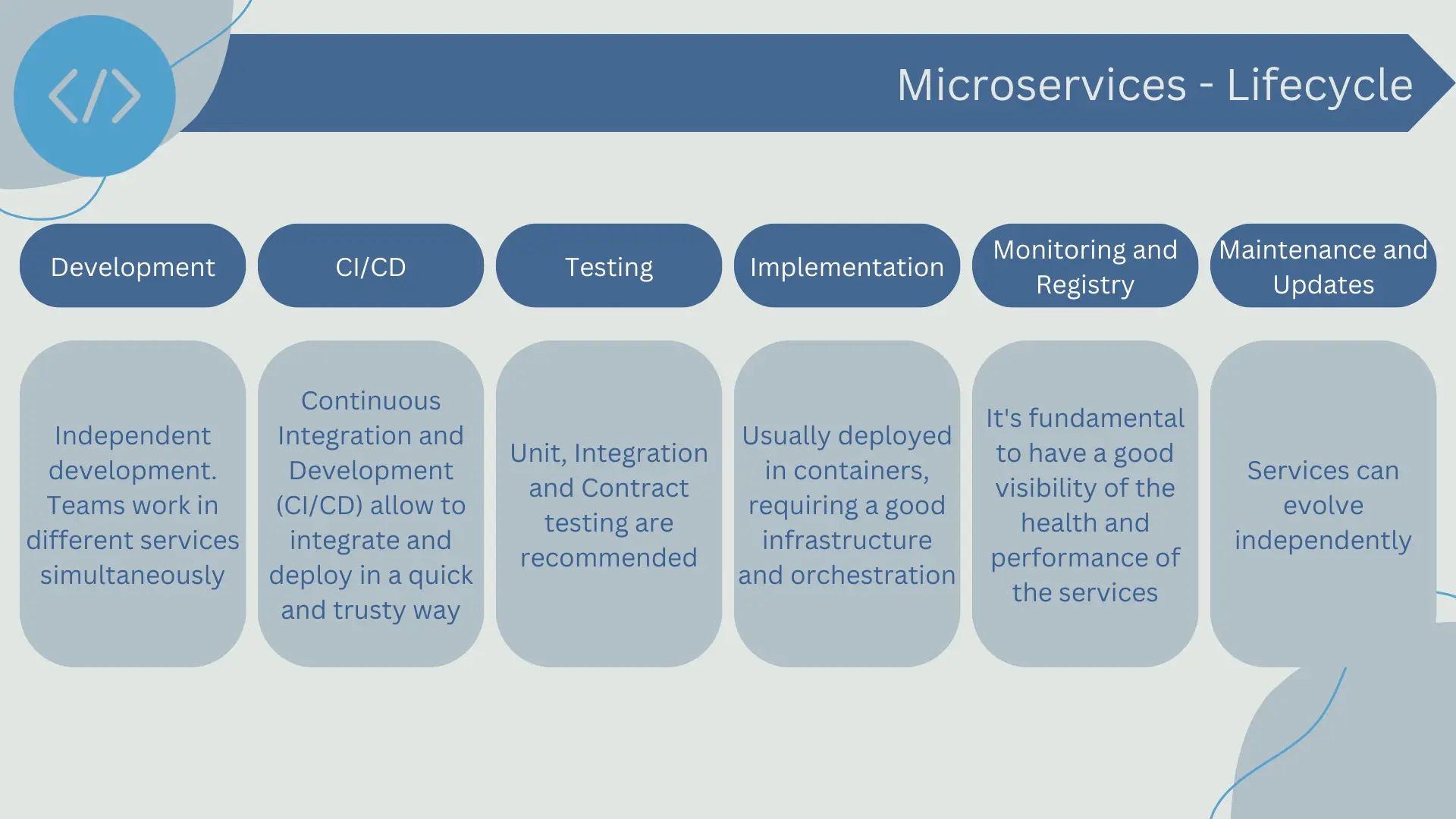
The development lifecycle of microservices is significantly different from that of monolithic applications and can be a challenge for organizations accustomed to traditional software development approaches.
- Independent Development: One of the key benefits of microservices architecture is that each service can be developed, deployed, and scaled independently. This allows development teams to work on different services simultaneously without interfering with each other. It also means that each service can be developed using the technologies and tools that best suit its specific purpose.
- Continuous Integration and Continuous Delivery (CI/CD): Continuous integration and continuous delivery (CI/CD) are essential practices in microservices development. CI/CD enables development teams to integrate and deploy changes quickly and reliably, which is especially important in a microservices environment where there are many independent services that need to coordinate with each other.
- Testing: Testing in a microservices architecture can be challenging due to the number of independent services and the interactions between them. It's important to have a robust testing approach that includes unit testing, integration testing, and contract testing to ensure that all services function correctly both individually and together.
- Deployment: Deploying microservices typically involves creating containers for each service, which are then deployed in a container runtime environment. This can quickly become complex as the number of services increases, so having good container management infrastructure and tools is essential.
- Monitoring and Logging: Monitoring and logging are critical in a microservices environment due to the large number of services and interactions between them. It's important to have good visibility into the health and performance of each service, as well as the interactions between services.
- Maintenance and Evolution: Unlike a monolithic application where application evolution may require changes throughout the entire codebase, in a microservices architecture, each service can evolve independently. This can allow for greater innovation speed but can also lead to coordination and consistency challenges.
The development lifecycle of microservices has its own challenges and complexities, but it also offers many opportunities for increased agility and development speed. It's essential to have a good understanding of these aspects and adopt the appropriate practices and tools to effectively manage them.
Use cases
Microservices are particularly useful in certain use cases, especially when scalability, development speed, and adaptability are key factors. Here are some typical use cases:
- Large-scale applications: Large-scale applications that require high availability, reliability, and scalability can greatly benefit from microservices architecture. Instead of building a monolithic application that can be difficult to scale and maintain, developers can build many small microservices applications that can be independently scaled, deployed, and maintained.
- Organizations with multiple development teams: Organizations with multiple development teams can find that microservices architecture helps them work more efficiently. Each team can focus on a specific service, using the technologies and tools that best suit their needs.
- Applications that need to be highly resilient: Microservices architecture can provide high resilience as a failure in one service should not affect the operation of others. This can be especially useful for applications that cannot afford any downtime.
- Applications that require rapid time to market: Microservices can speed up time to market by allowing development teams to work in parallel on different services. They can also facilitate rapid iteration as changes can be deployed to a specific service without affecting others.
- Modernization of existing applications: Microservices architecture can be helpful for organizations that are trying to modernize existing applications. Instead of rewriting the entire application from scratch, they can decompose the existing application into microservices that can be modernized independently.
Despite these benefits, it's important to note that microservices are not the right solution for every use case. Smaller or less complex applications may not benefit from microservices architecture and may find a monolithic or single-server approach more suitable. Additionally, microservices can add significant complexity and require a considerable investment in terms of infrastructure and development skills. Therefore, it's crucial to carefully consider the specific needs and capabilities of the organization before adopting microservices architecture.