
Layered architecture, also known as tiered architecture, is one of the most common software architecture patterns. It is based on the idea of dividing an application into a set of logical layers, each with a specific responsibility. This design pattern is widely used due to its organized structure, modularity, and ability to separate concerns.
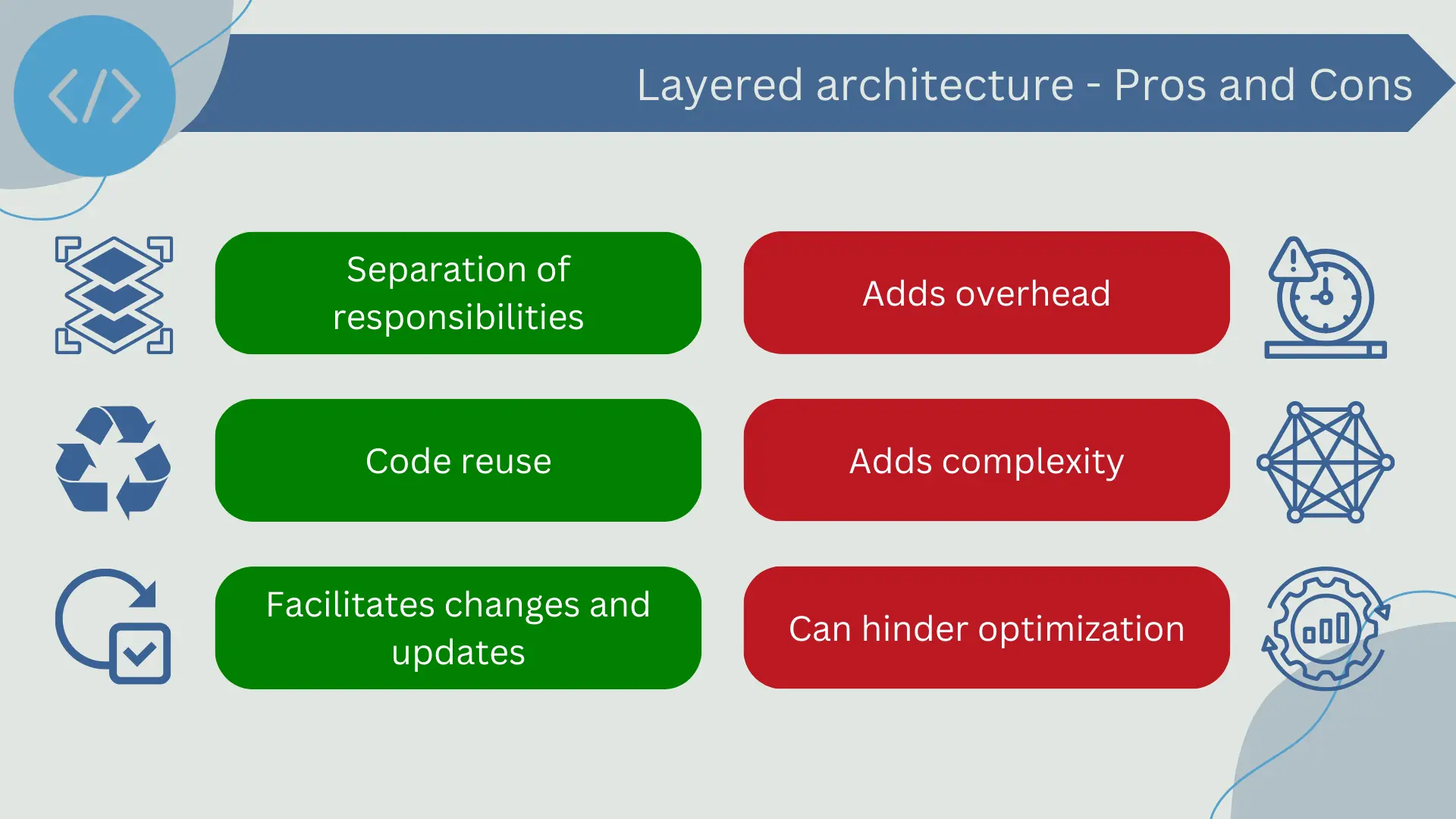
Using this architecture provides certain benefits, such as:
- Separation of Responsibilities: Each layer has its own set of responsibilities, allowing for a cleaner design and easier maintenance. Business logic, user interface, and data access logic are clearly separated, which can facilitate understanding of the system.
- Code Reusability: Logic that is common to different parts of the application can be encapsulated in a layer and reused throughout the application. This can lead to reduced code redundancy and code that is easier to maintain.
- Facilitates Changes and Updates: With a well-designed layered architecture, it is possible to change or update one layer without affecting the others. For example, you could change your database engine (in the data access layer) without having to modify the business logic or user interface.
However, there are certain drawbacks to consider when choosing this pattern:
- Performance: Each layer adds a certain amount of overhead in terms of performance, as requests must pass through each layer. In some high-load applications, this overhead can be significant.
- Complexity: While a layered architecture can make the system easier to understand in some aspects, it can also add complexity. It may be more difficult to design a well-organized system with clearly defined layers than a simpler system without layers.
- Can hinder optimization: Due to the rigid separation of responsibilities, it can be challenging to perform optimizations that span multiple layers. For example, implementing functionality that requires close interaction between business logic and the database could be difficult.
Internal Structure of Layered Architecture
The internal structure of layered architecture is designed to separate different responsibilities of the application into logical segments. Each layer has a specific purpose and provides services to the layer above it. In its most common form, a software application is divided into three main layers: presentation, business logic, and data access.
- Presentation Layer: This is the topmost layer of the application and is the only layer that users directly interact with. The presentation layer is responsible for collecting user inputs and displaying the results of the application's processing. In a web application, this layer is implemented using user interface technologies such as HTML, CSS, JavaScript, and frameworks like React, Angular, or Vue.js.
- Business Logic Layer: This is the middle layer and acts as a mediator between the presentation layer and the data access layer. The business logic layer implements the business rules, such as algorithms and functions that handle the exchange of information between the presentation layer and the data access layer. This layer can be developed using various programming languages like Java, Python, C#, etc., and may include frameworks like Spring, Django, .NET Core, etc.
- Data Access Layer: This is the bottom layer that directly interacts with databases or any other data storage systems. The data access layer is responsible for storing and retrieving data from the database and providing an interface to the business logic layer to perform these operations. This layer can use technologies like SQL, NoSQL, Object-Relational Mapping (ORM) frameworks, etc.
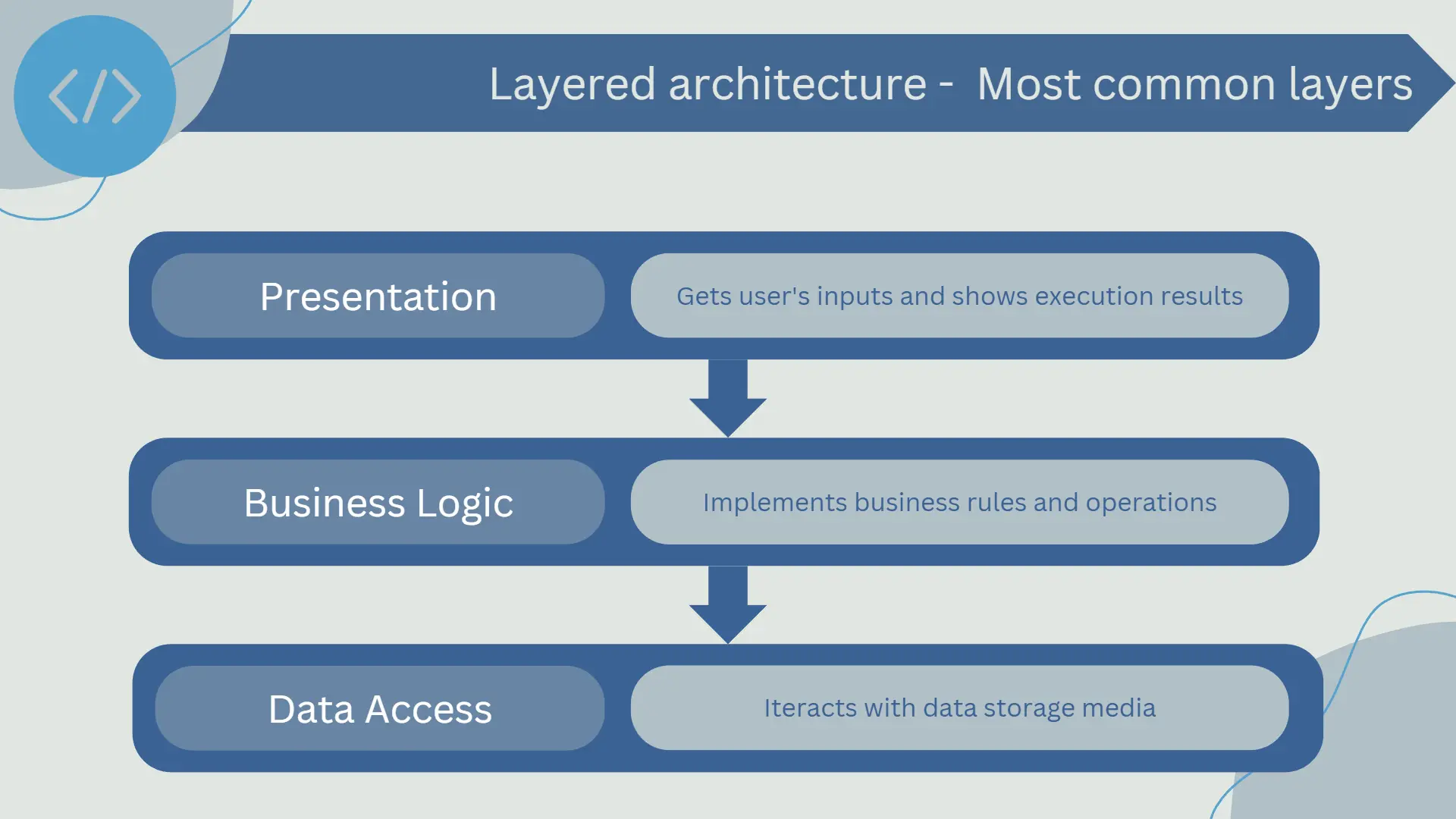
The three layers are interconnected in such a way that each layer only knows and communicates with the layer immediately below or above it. For example, the presentation layer knows about the business logic layer but has no idea about how data is handled in the data access layer. This layer isolation helps maintain the application flexible, easy to maintain, and scalable.
Layered architecture also has significant implications in terms of infrastructure and code organization. Some considerations to keep in mind include:
- Code Organization: The code for each layer is typically organized into separate packages, modules, or namespaces. This improves code readability and maintainability and helps ensure that each piece of code only has the dependencies it truly needs. For example, you could have a package for the presentation layer that includes all user interface controllers, a package for the business logic layer that contains all business rules and operations, and a package for the data access layer that handles all interactions with the database.
- Layer Isolation and Independence: Ideally, each layer should be independent and only interact with adjacent layers. For example, the business logic layer should only interact with the presentation layer and the data access layer, not directly with the database or the user interface. This isolation helps maintain the cohesion of each layer and reduces unnecessary dependencies.
- Communication between Layers: Layers communicate with each other through well-defined interfaces. This allows layers to be interchangeable as long as they implement the correct interface. For example, you could change the implementation of the data access layer from a SQL database to a NoSQL database, and as long as it implements the same interface, the rest of the application wouldn't have to change.
- Physical Infrastructure: In terms of physical infrastructure, the different layers of an application are often hosted on the same machine in a monolithic architecture. However, in a more distributed or cloud architecture, each layer may be hosted on its own server or set of servers to allow scalability and availability. For example, you could have separate servers for your database, your business logic, and your user interface.
Presentation Layer
The presentation layer, also known as the user interface layer or user layer, is the layer of a software application that directly interacts with the user. This layer manages how information is displayed to the user and how the user interacts with the application. Depending on the type of application, the presentation layer can include a graphical user interface (GUI), a command-line interface (CLI), or an interface for a web application.
Key components of the presentation layer include:
- User Interface: The user interface is the medium through which the user interacts with the application. In a web application, the user interface may include HTML elements such as buttons, forms, dropdown menus, etc. In a desktop application, it might include windows, buttons, text fields, and other widgets.
- User Interface Logic: User interface logic is the code that manages user interactions with the user interface. This logic can include things like what happens when the user clicks a button, how user input is validated, how input errors are handled, and how user interface elements are updated in response to user actions.
- Data Rendering: The presentation layer is responsible for presenting data to the user in a way that is easy to understand. This may involve converting raw data into a more readable format, applying styles and formatting, or even translating data into a different language.
- User Session and State Management: In some applications, the presentation layer may also be responsible for managing user sessions and user state. This can involve things like tracking user activity, storing user preferences, and keeping the user logged in between visits.
The presentation layer is critical to the user experience, so its design and development often require careful consideration of UI design, usability, and accessibility.
Business Logic Layer
The business logic layer, also known as the processing layer or domain layer, is an essential part of any software system. This layer is responsible for implementing the rules, operations, and algorithms that govern the core functionality of an application, i.e., the "what" and "how" of the application's functionality.
Key components of the business logic layer include:
- Business Rules: Business rules are statements that dictate how the business operates. These rules define the operations, workflows, data validation, calculations, and decisions that are fundamental to the functioning of the business. These rules are implemented in the business logic layer.
- Business Operations: Business operations are the tasks and procedures carried out by the business. This can include creating, reading, updating, and deleting data (CRUD operations), calculations, transaction processing, and other business procedures.
- Domain Models: Domain models are representations of the business entities and the relationships between them. These models can include classes, interfaces, and methods that represent business objects such as a customer, a product, an order, etc.
- Orchestration and Coordination: The business logic layer may also be responsible for coordinating and orchestrating transactions between different systems and components. This can include transaction management, error and exception handling, and ensuring data consistency.
The design of the business logic layer can vary considerably depending on the nature of the application. Some applications may have relatively simple business logic, while others may have highly complex business logic with many rules, operations, and domain models.
It is important that the business logic layer is well-designed and properly separated from the presentation and data access layers. This facilitates maintainability, allows code reuse, and helps ensure that the business logic is implemented consistently and accurately throughout the application.
Data Access Layer
The data access layer, also known as the persistence layer or data layer, is responsible for communicating with the data sources of the application, which can be databases, web services, file systems, among others. Its main objective is to abstract and encapsulate data access operations, providing a unified and consistent way to interact with them, regardless of their source or format.
Key components of the data access layer include:
- Data Access Interfaces: These interfaces define the methods that will be used to interact with the data, such as creating, reading, updating, and deleting records (CRUD operations), as well as search and filtering operations. These interfaces provide an abstraction that hides the implementation details of data manipulation.
- Data Access Implementation: This is the part of the data access layer that directly interacts with the data source. It can use database query languages (such as SQL), web service calls, or file system APIs to perform data access operations.
- Object-Relational Mapping (ORM): In object-oriented applications, a pattern known as Object-Relational Mapping (ORM) is often used to translate between the representation of data in the database and objects in the application. This allows developers to work with data as if they were application objects, simplifying the interaction with the data.
- Connection Management: The data access layer is also responsible for managing connections to the data sources. This can include opening and closing connections, managing connection pools, and handling connection errors.
- Transactions: If the application needs to perform operations that involve multiple steps that must be completed together (such as transferring money between bank accounts), the data access layer may also be responsible for managing these transactions to ensure data integrity.
When designing the data access layer, it is important to consider principles of encapsulation and abstraction. This can help improve code modularity and reusability, facilitate testing and maintenance of the application, and allow for changing the data source without affecting the rest of the application.
Request Handling in Layered Architecture
In a layered architecture, request handling follows an ordered and predictable flow through the different layers of the application. While the specific layers may vary depending on the application, the following describes a typical request flow:
- Request Initiation: It all begins with a user request in the presentation layer. This could be, for example, a button click on a web page, an input in a form, or a command from a desktop application
- Presentation Layer: The presentation layer collects the user input and transforms it into a request understandable by the business logic layer. For example, if the user clicks a button to view all products, the presentation layer might create a request like "GetAllProducts".
- Business Logic Layer: Once the business logic layer receives the request, it processes the information according to the business rules. In the case of a "GetAllProducts" request, the business logic layer would send a request to the data access layer to retrieve information for all products.
- Data Access Layer: The data access layer receives the request from the business logic layer, interacts with the database or any other storage system to retrieve the necessary data, and returns the data to the business logic layer.
- Response to the Request: The business logic layer receives the data from the data access layer, processes the data if necessary, and then sends the response to the presentation layer. The presentation layer finally presents the data to the user in an understandable manner.
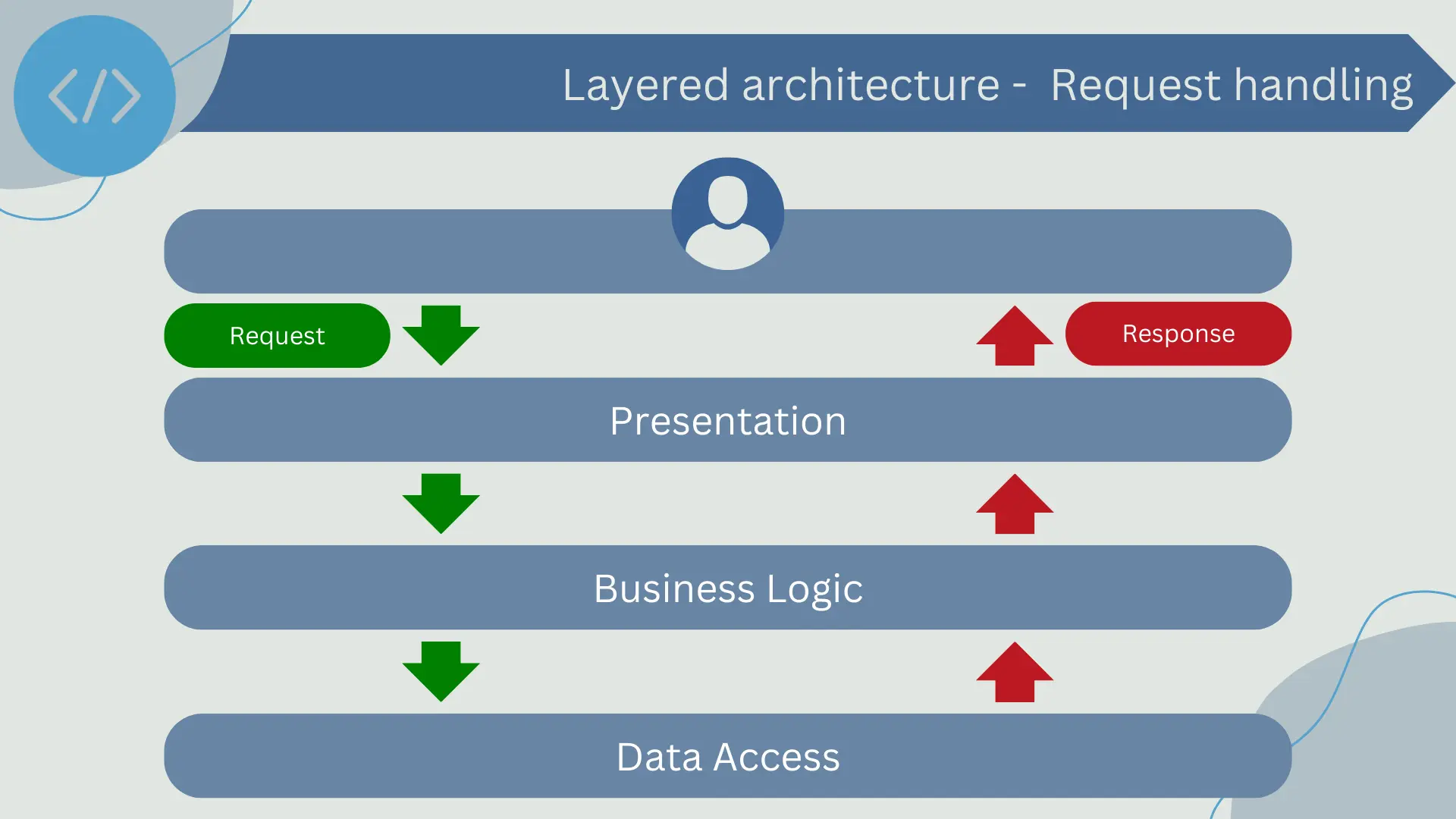
This request and response flow ensures that each layer has well-defined responsibilities and only interacts with the immediate layer above or below it. This not only keeps the application well-organized but also facilitates modifying or replacing an individual layer without affecting the others.
Scalability of Layered Architecture
Scalability is an important consideration for any software architecture, and layered architecture is no exception. It refers to the ability of a system to handle an increasing amount of work or its potential to expand and accommodate that growth.
In a layered architecture, scalability can be achieved through both vertical scaling (adding more computational power to a single machine) and horizontal scaling (adding more machines to the system).
- Vertical Scalability: In vertical scalability, the capacity of an individual machine is increased by adding more resources such as CPU, memory, or storage. In a layered architecture, this could involve enhancing the capacity of the machine hosting a specific layer. For example, if the business logic layer is experiencing the highest utilization, performance could be improved by increasing the resources of that specific machine.
- Horizontal Scalability: Horizontal scalability involves adding more machines to the system to distribute the workload. In a layered architecture, this could be done at each individual layer. For instance, if the data access layer is identified as a bottleneck, additional database servers could be added to distribute the load among them. Similarly, the business logic layer could be distributed across multiple servers to balance the load and enhance performance.
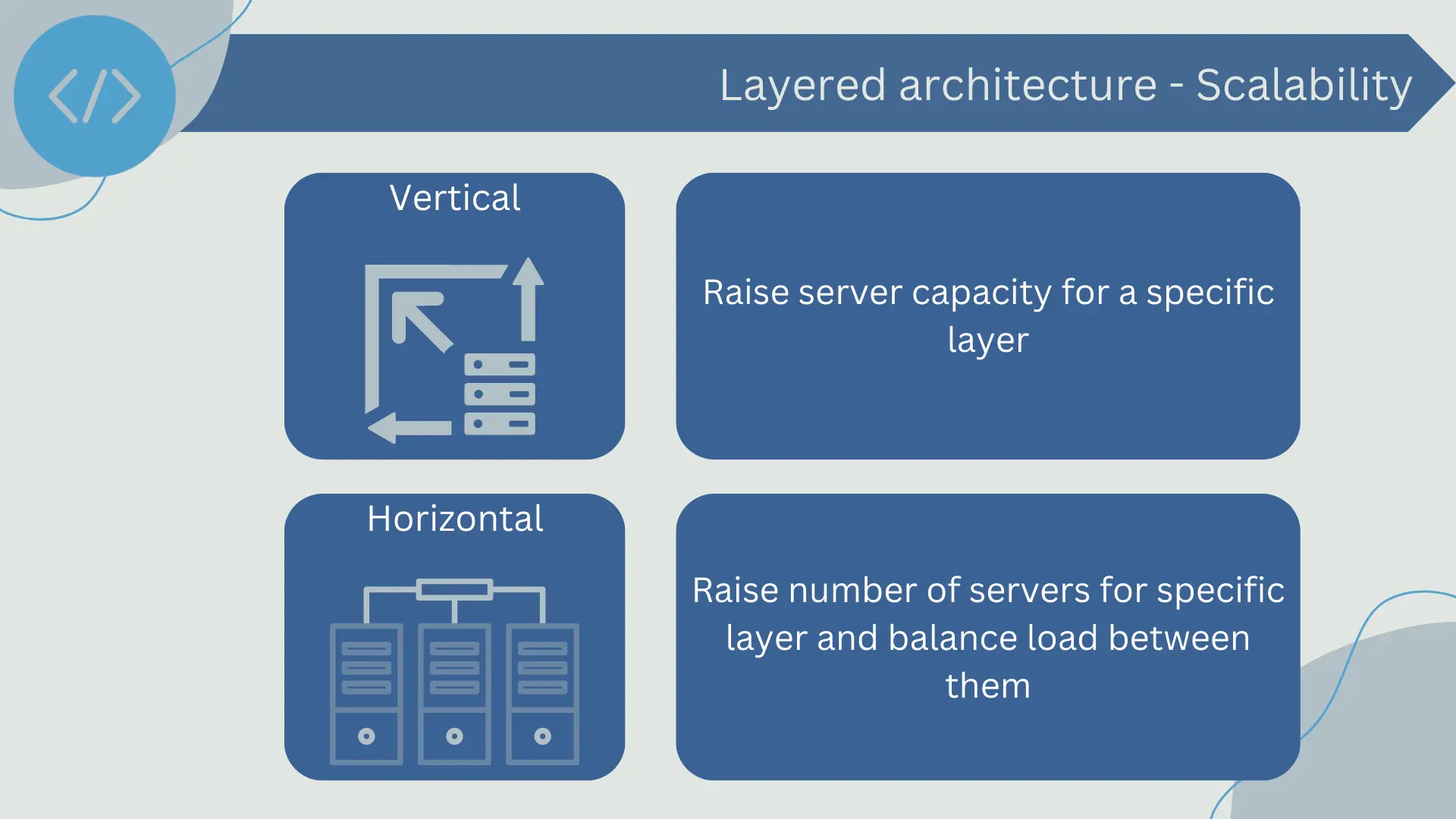
While layered architecture can be scaled both vertically and horizontally, it may have scalability limitations due to its tight dependency between layers. For example, if a layer cannot handle the number of requests it receives from the layer above, it can become a bottleneck for the entire application.
On the other hand, microservices architecture, which is an evolution of layered architecture, addresses this issue by allowing each service (which can be a layer or a combination of layers) to scale independently. This can be especially useful in large and complex applications where different parts of the application may have different scalability requirements.
Development and Lifecycle of Layered Architecture
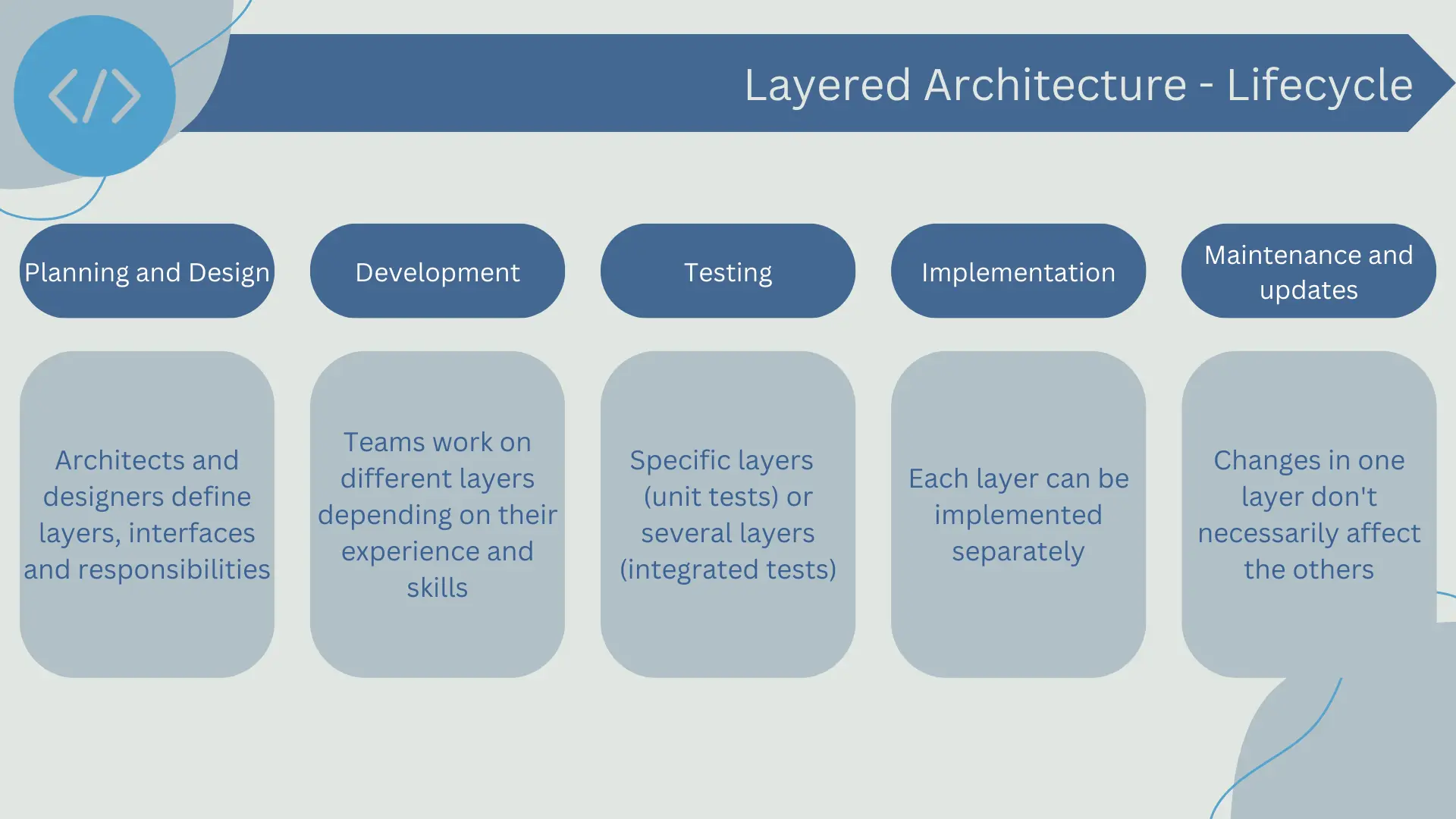
The development and lifecycle of a layered architecture follow a structured process, making it easier to plan, implement, and maintain the software. Here's how a system based on layered architecture can be developed and maintained:
- Planning and Design: Before writing any code, software architects and designers define the layers that will compose the application, as well as the responsibilities and interactions of each layer. This step is crucial for establishing a solid structure for the application.
- Development: In this stage, development teams create each layer of the application. It's common for different teams to work on different layers, depending on their expertise and skills. For example, frontend developers may work on the presentation layer, while backend developers focus on business logic and data access.
- Testing: Testing is an integral part of the software development lifecycle. In a layered architecture, testing can be conducted on each layer independently (unit testing) as well as between layers (integration testing) to ensure that the layers interact correctly.
- Deployment: Once the application has been developed and tested, it is deployed in the production environment. In layered architecture, deployment can be simpler than in other architecture models since each layer can be deployed independently.
- Maintenance and Updates: Throughout its lifecycle, the application will require maintenance and updates. In a layered architecture, these tasks can be easier to manage, as changes in one layer don't necessarily affect the other layers.
Layered architecture also offers great flexibility for the growth and evolution of the application. For example, if an application needs to change its database, only the data access layer needs to be modified, without impacting the business logic or presentation layer. Similarly, if a change is needed in the user interface, only the presentation layer needs to be modified.
Use Cases of Layered Architecture
Layered architecture is one of the most common software architectures due to its simplicity and flexibility. Here are some use cases where layered architecture can be particularly useful:
- Enterprise Applications: Enterprise applications often require a well-organized structure and the ability to separate different responsibilities and functions. Layered architecture provides this clear organization, making it easier to maintain and update applications over time.
- Web Applications: Many web applications use layered architecture due to its scalability and clear separation between the user interface and business logic. This facilitates development, as frontend and backend teams can work independently on their respective layers.
- Information Systems: Information systems such as Customer Relationship Management (CRM) systems or Enterprise Resource Planning (ERP) systems benefit from layered architecture as they often have different levels of users with different needs. The layer separation allows for developing user interfaces specific to each user level while maintaining consistent business logic.
- Software as a Service (SaaS) Applications: SaaS applications, which are accessible over the internet, benefit from layered architecture due to its ability to scale and adapt to a growing number of users. With layered architecture, each layer can scale independently to meet the demands of the application.
- Legacy System Migration: Legacy systems can be challenging to maintain and update. By adopting layered architecture, organizations can replace or modernize individual pieces of the application (one layer at a time) without disrupting the entire system.
Of course, while layered architecture is versatile, it is not the perfect solution for all cases. For highly distributed applications or those requiring aggressive scalability, other architectures such as microservices may be more suitable.