
Event-driven architecture is a model in which the flow of the application is determined by the occurrence of events or changes in state. These events are detected and handled by software components, which contain the application logic, to perform specific actions. The trigger for logic in these systems is not a direct call from one component to another, but the generation and handling of events.
In an event-driven architecture, three basic roles can be distinguished:
- Event emitters: These are the system components that generate events and publish them to the event bus.
- Event bus: It is the communication mechanism that transmits events from emitters to receivers.
- Event receivers: These are the system components that are interested in certain types of events and subscribe to them. When an event of interest occurs, the receiver is notified and reacts according to its internal logic.
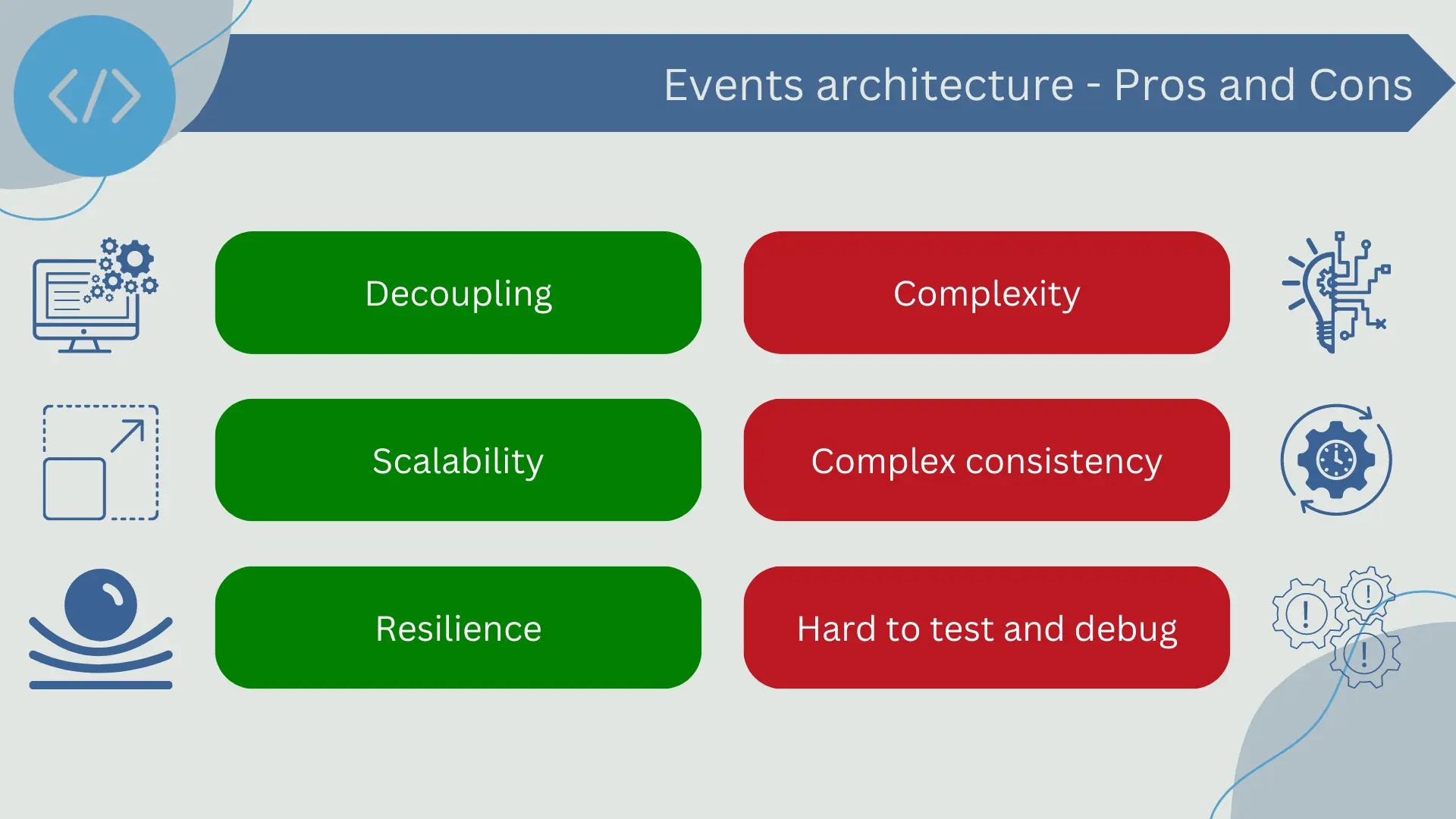
Using this type of architecture has several advantages:
- Decoupling: In an event-driven architecture, event emitters and receivers are decoupled. Emitters do not need to know who will process their events, and vice versa. This facilitates change and evolution of a system over time.
- Scalability: Event-driven architectures are highly scalable as events can be processed in parallel, and components can be added or removed independently without affecting the rest of the system.
- Resilience: In case of failures, event-driven systems can be more resilient. If a component fails, it only affects that component and the events it was processing.
However, there are several disadvantages to consider before choosing it:
- Complexity: Event-driven architecture can introduce additional complexity as the application logic may be distributed across many components. This can make the application harder to understand and debug.
- Consistency: Maintaining data consistency can be a challenge in event-driven systems as events can be processed in parallel and in any order.
- Testing and debugging: The asynchronous and decentralized nature of event-driven systems can make testing and debugging more difficult. Understanding the flow of the application and finding the source of problems can be challenging.
Structure
Event-driven architecture has a very different structure compared to more traditional architectures. It focuses on the production, detection, and reaction to events, where an event is a meaningful state change in the context of the business or application.
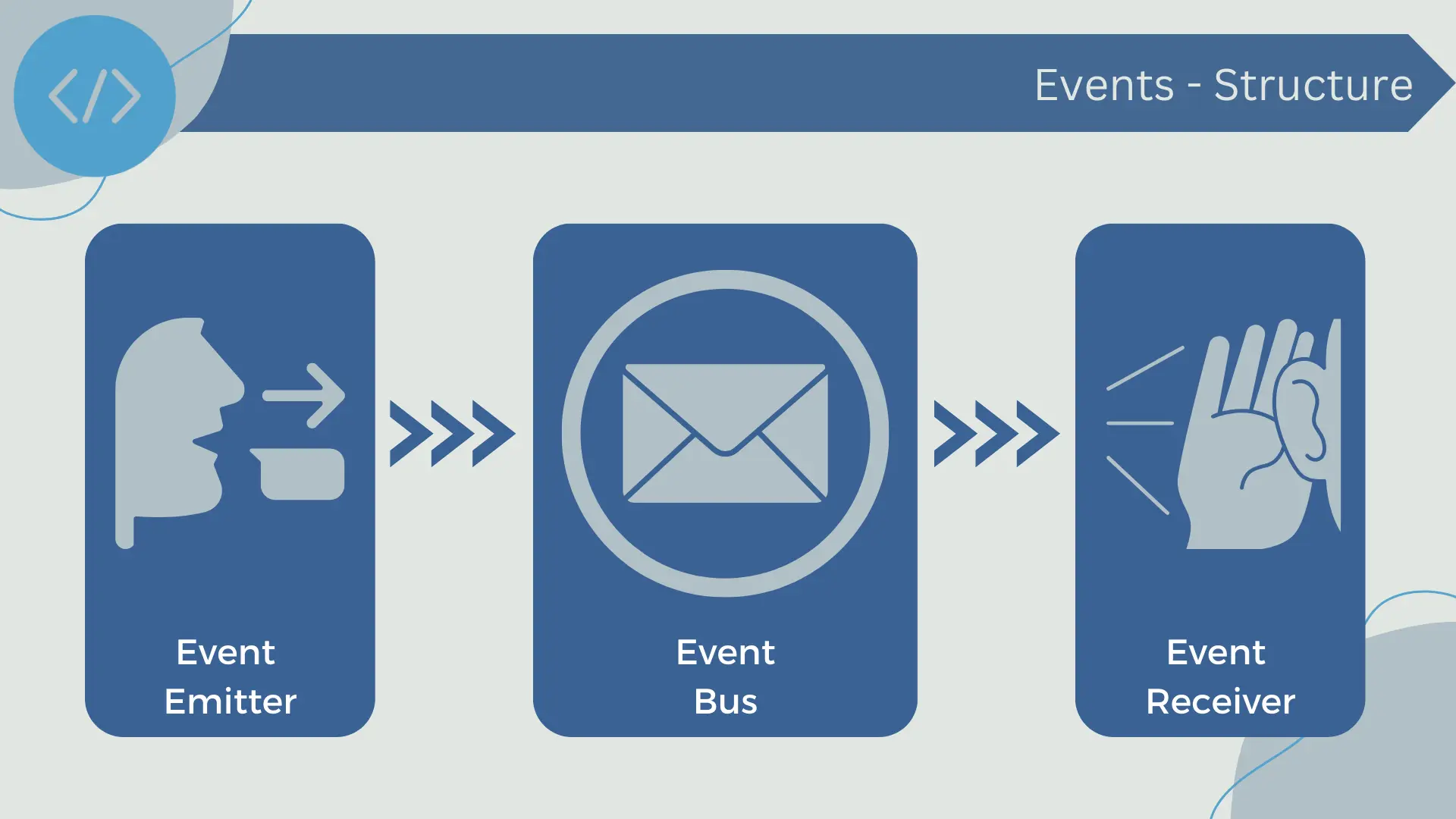
The structure of an event-driven system generally consists of the following elements:
- Event emitters: Emitters are system components that generate or publish events. An event is generated as a result of a relevant state change in the system. For example, an e-commerce system may generate an event when a customer places an order.
- Event bus: The event bus is the communication infrastructure that allows event emitters to publish events and event receivers to subscribe to them. It can be a message queue, a pub/sub messaging system, a data stream, or any other infrastructure that facilitates event exchange.
- Event receivers: Receivers are system components that are interested in certain types of events and react to them. When a receiver receives an event it has subscribed to, it performs an action or a series of actions in response. This action could be, for example, sending a confirmation email when an event indicating that a customer has placed an order is received.
In this architecture, event emitters do not need to know about the receivers of their events. This means that components are decoupled, providing flexibility and enabling the system to scale and evolve easily.
At the organizational level, components are often distributed and organized based on business needs. Components dealing with the same business area can be grouped into a module or service.
At the core of this type of architecture is the idea that any state change in the system can be turned into an event that can be published, and any behavior in the system can be modeled as a reaction to one or more events.
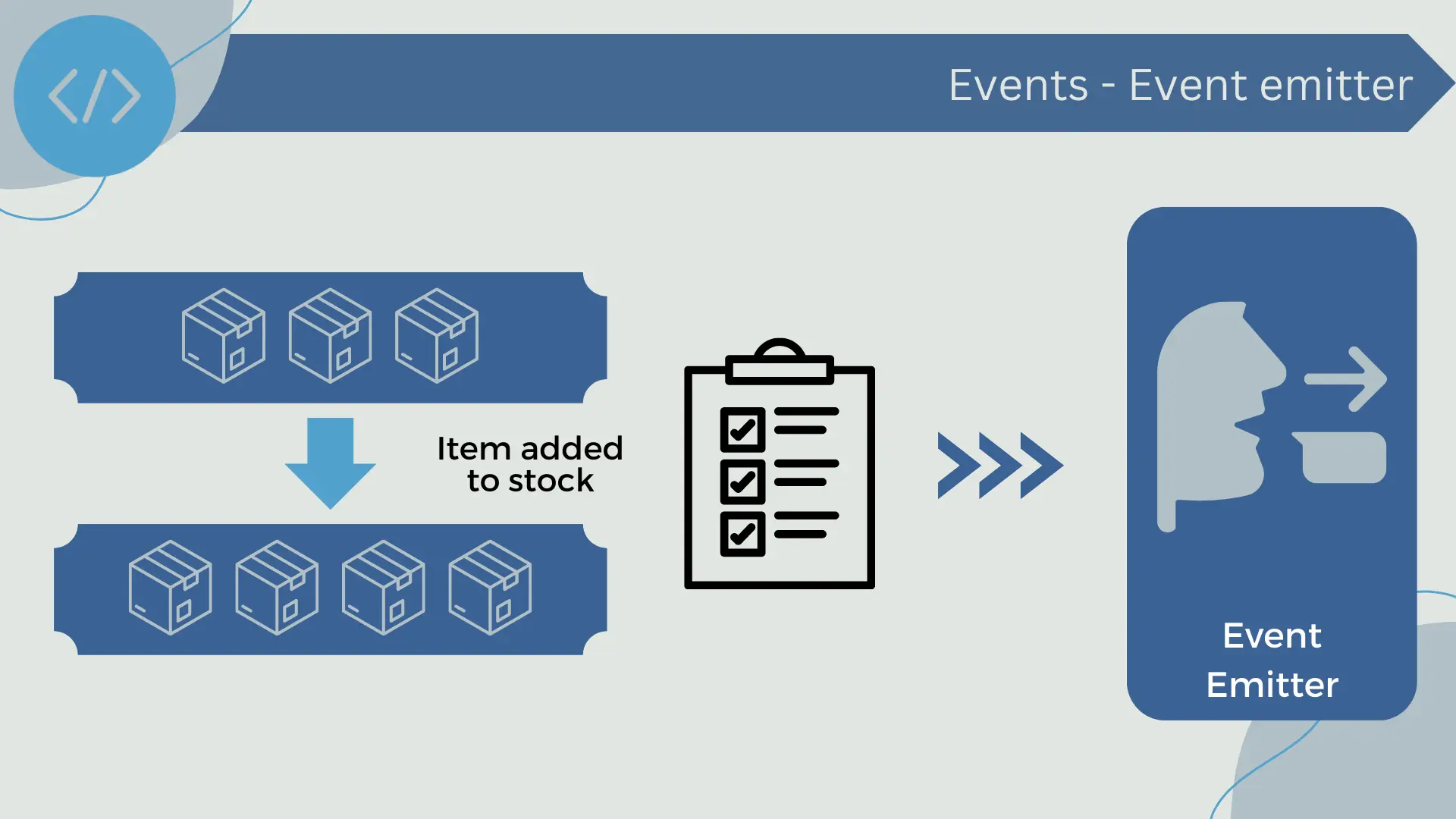
Event Emitters
Event emitters are the components or actors in a system that make significant state changes and then emit or publish events to announce these changes. In an e-commerce context, for example, an event emitter could be an inventory management system that generates an event whenever the available quantity of a product changes.
Event emitters are integral to event-driven architecture because they are the source of the data that drives the system's behavior. Without event emitters, there would be no events to handle, and therefore, no changes in the system's state.
The design and implementation of event emitters can vary greatly depending on the application's needs and the specific technologies being used. Generally, however, event emitters must be able to detect significant state changes, generate events that represent these changes, and then publish these events so that they can be handled by event receivers.
To generate an event, an event emitter may need to collect data from various sources such as databases, file systems, message queues, sensors, and other system components. Once it has gathered all the necessary data, the event emitter creates an event object, which is essentially a data package containing all the relevant information about the state change.
Once the event has been generated, the event emitter publishes it to the event bus. This usually involves sending the event object to the communication infrastructure that implements the event bus. Once the event has been published, it is available for any interested event receiver to handle.
Event Bus
The event bus, also known as an event channel or message broker, is a key component in event-driven architecture. Its role is to provide an effective means of communication and coordination between event emitters and event receivers.
An event bus acts as an intermediary that accepts events from emitters and distributes them to receivers that have indicated an interest in those types of events. In this sense, the event bus plays a crucial role in ensuring that events reach the appropriate recipients.
This bus can be implemented in various ways depending on the application's needs and system characteristics. Some common implementations include message queues, publish/subscribe (pub/sub) systems, and data streaming systems.
- Message queues: In this model, emitters place events in a queue, and receivers retrieve them from the queue. Message queues often ensure the delivery of events but not necessarily in the order they were sent.
- Publish/subscribe systems: In this model, emitters publish events to a topic, and receivers subscribe to topics they are interested in. Pub/sub systems allow for more immediate delivery of events compared to message queues and can support a large number of emitters and receivers.
- Data streaming systems: In this model, emitters send events to a data stream, and receivers read events from the stream. Data streaming systems are useful for applications that need to process large volumes of events in real-time.
Regardless of the specific model used, the event bus enables decoupling between emitters and receivers, facilitating scalability and system evolution.
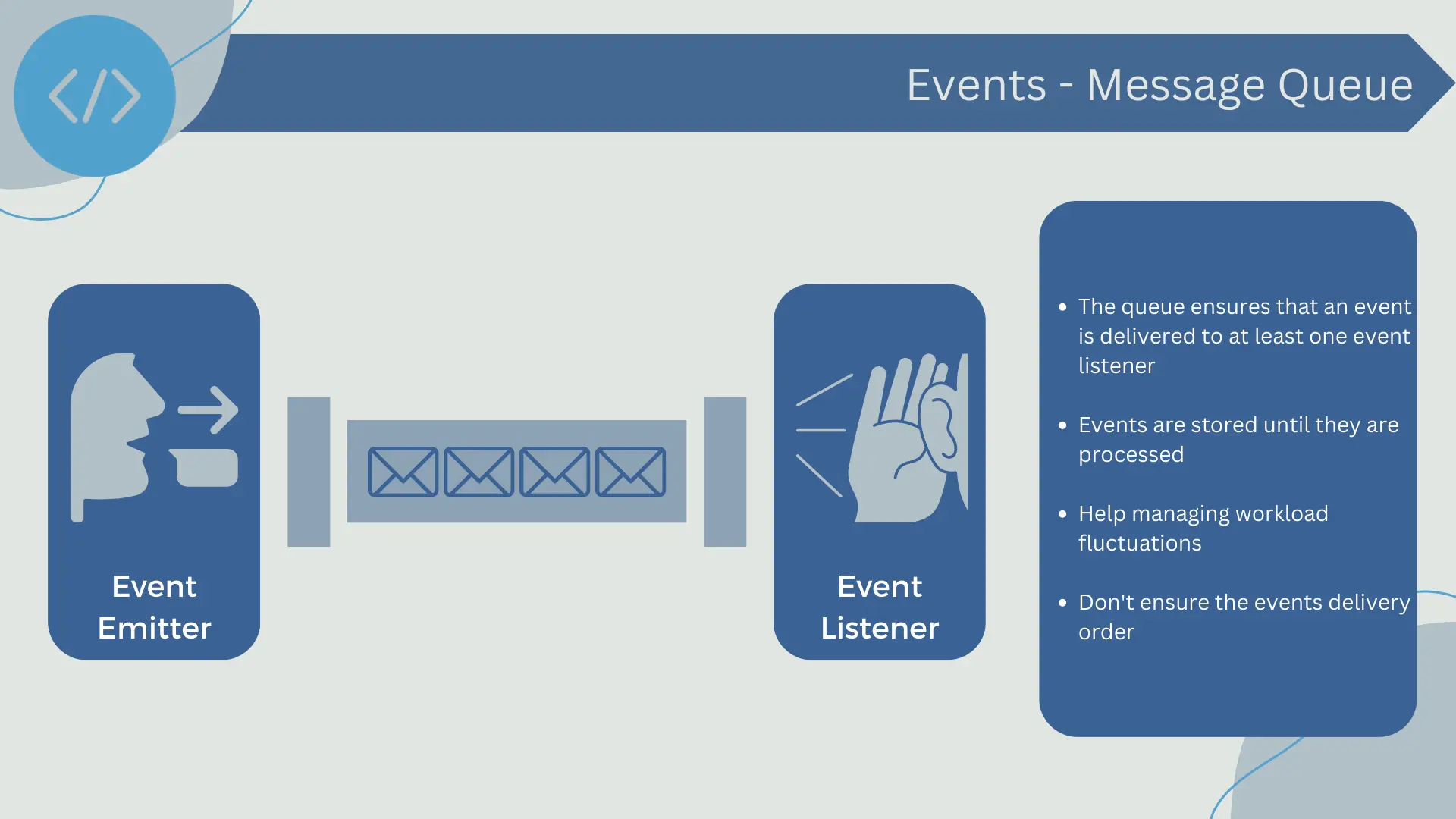
Message Queues
Message queues are a common way to implement an event bus in an event-driven architecture. In this model, event emitters send or "place" their events into a queue, and event receivers "consume" the events from the queue for processing.
One of the main features of message queues is that they provide a reliable message delivery mechanism. This means that once an event emitter has placed an event in the queue, the queue ensures that the event will be delivered to at least one event receiver. If the event receiver fails for some reason while processing the event, the queue may attempt to deliver the event to another receiver or retry the delivery to the same receiver once it has recovered.
In a message queue, events are stored until they are processed by a receiver. This means that message queues can provide a certain degree of fault tolerance. If the system crashes for some reason, the events in the queue are not lost and can be processed once the system recovers.
Additionally, message queues can help handle fluctuations in workload. If there is a peak in the number of events being generated, the additional events are simply placed in the queue and processed when event receivers are available. Similarly, if there is a lull period with few events being generated, event receivers may remain idle without causing any issues.
However, message queues also have some disadvantages. One of the most significant is that they do not guarantee the delivery order of events. In other words, events may not be processed in the order they were placed in the queue. This can be a problem in situations where the order of events is important.
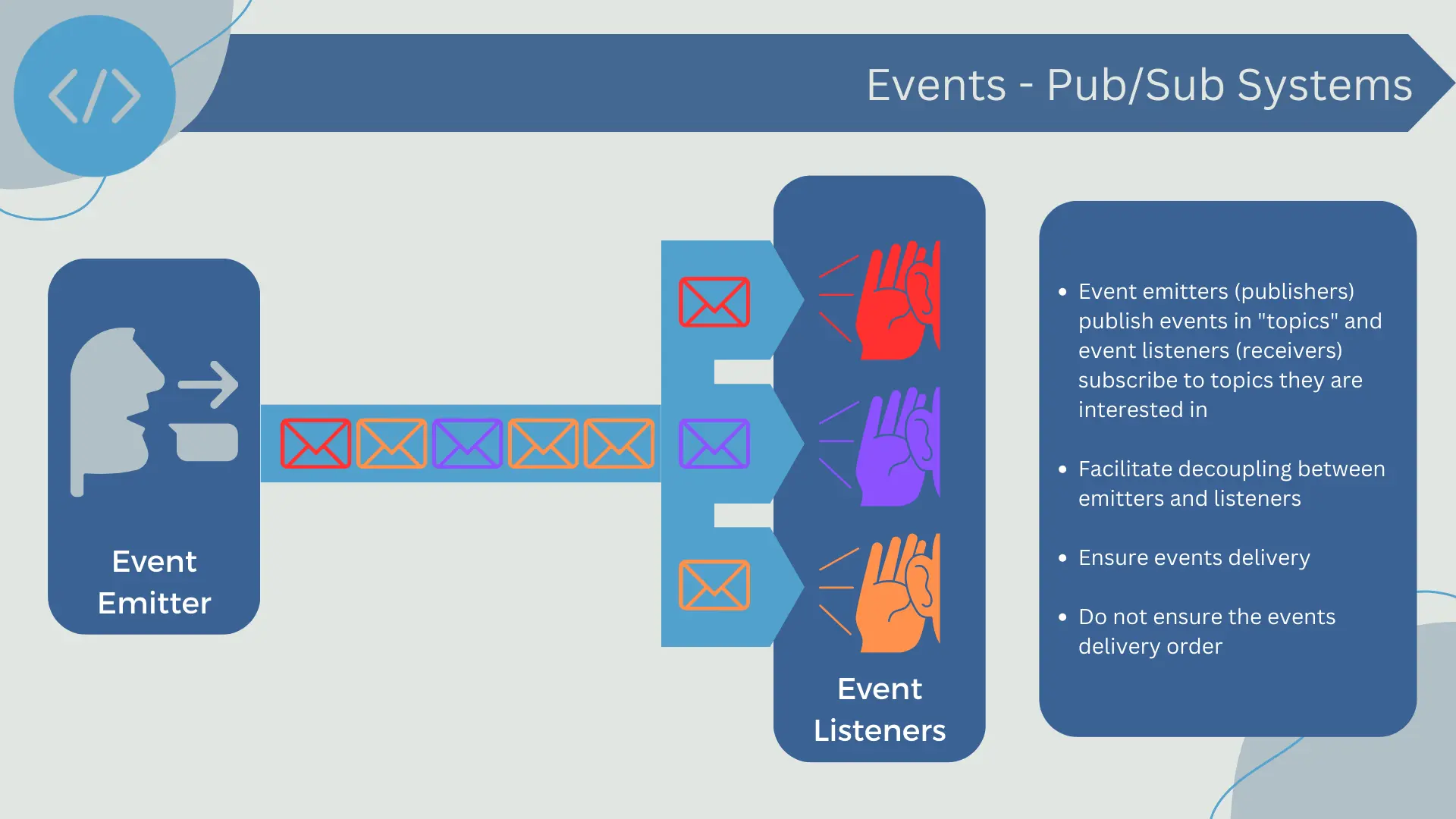
Publish/Subscribe Systems (Pub/Sub)
Publish/subscribe systems, also known as pub/sub systems, are another common way to implement an event bus. In this model, event emitters (publishers) publish events to "topics," and event receivers (subscribers) subscribe to the topics they are interested in.
When an event is published to a topic, the pub/sub system takes care of delivering that event to all subscribers of that topic. Therefore, pub/sub systems allow for event broadcasting to many subscribers, making it easy to implement systems with a large number of event emitters and receivers.
Pub/sub systems provide strong decoupling between event emitters and receivers. Event emitters do not need to know the identity or quantity of subscribers, and subscribers do not need to know the identity of emitters. This facilitates scalability of the system, as emitters and receivers can be added or removed without modifying the code of others.
Furthermore, pub/sub systems typically provide mechanisms to ensure event delivery. If a subscriber is unavailable or fails while processing an event, the system can retry event delivery or deliver the event to another subscriber.
However, like message queues, pub/sub systems do not guarantee the delivery order of events. Events may be delivered to subscribers in a different order than they were published. This can be a problem in situations where the order of events is important. However, some advanced pub/sub systems offer options to preserve the order of events.
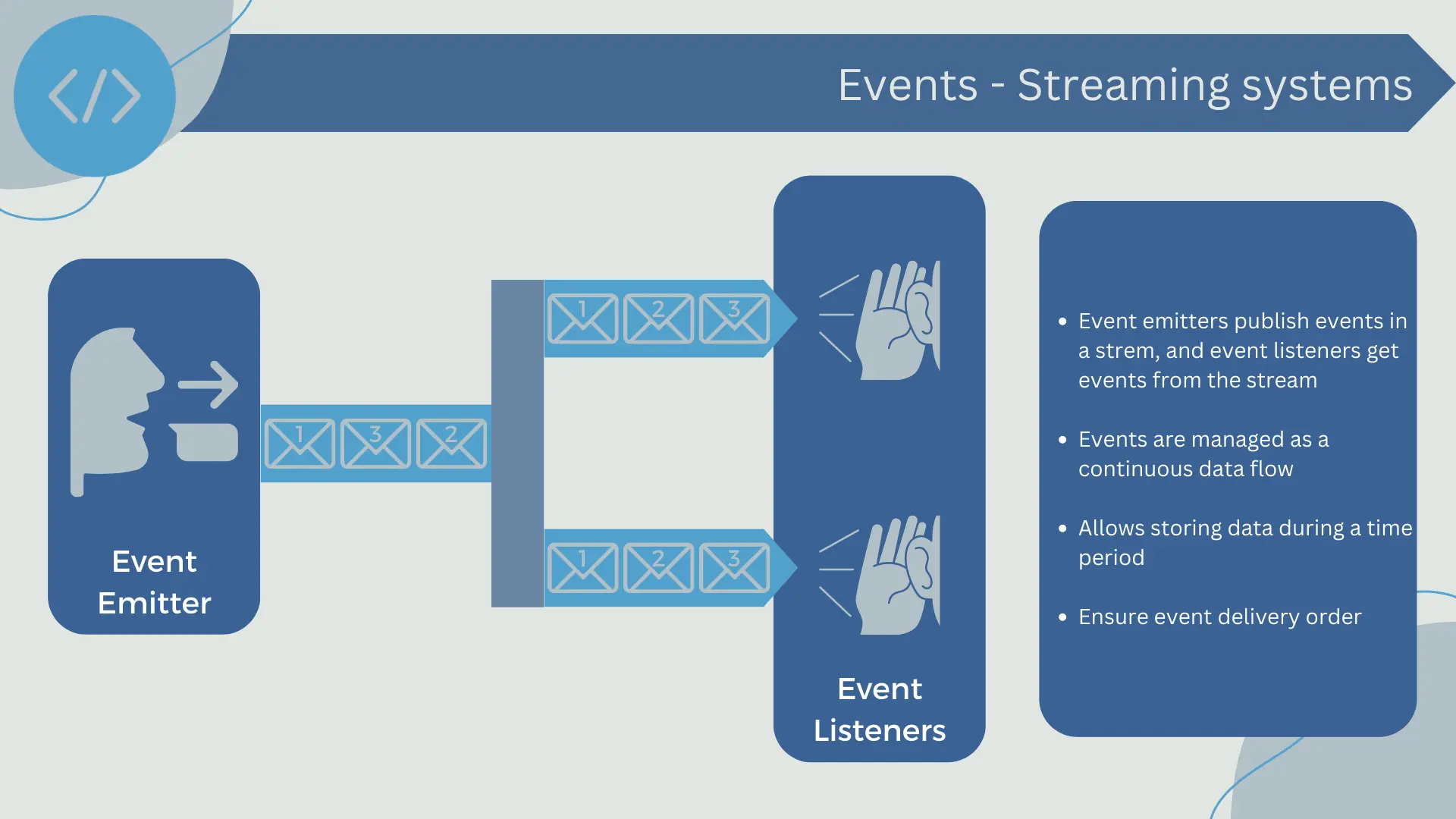
Data Streaming Systems
Data streaming systems are an evolution of message queues and pub/sub systems designed to handle large-scale real-time event streams. In a data streaming system, event emitters publish events to a "stream," and event receivers consume events from this stream.
Unlike message queues and pub/sub systems, which treat events individually, data streaming systems treat events as a continuous stream. This allows for implementing complex operations on the event stream, such as time windows, aggregations, and stream merging.
Additionally, many data streaming systems allow for event storage for a period of time. This means that event receivers can "rewind" the stream and reprocess past events if necessary. This is useful, for example, in case of failures or to implement new features that require processing of historical events.
Data streaming systems also provide strong decoupling between event emitters and receivers. Event emitters do not need to know the identity or quantity of consumers, and consumers do not need to know the identity of emitters.
Lastly, it is important to mention that data streaming systems can also guarantee the delivery order of events, which can be crucial in certain applications. However, this feature may come with performance and complexity costs.
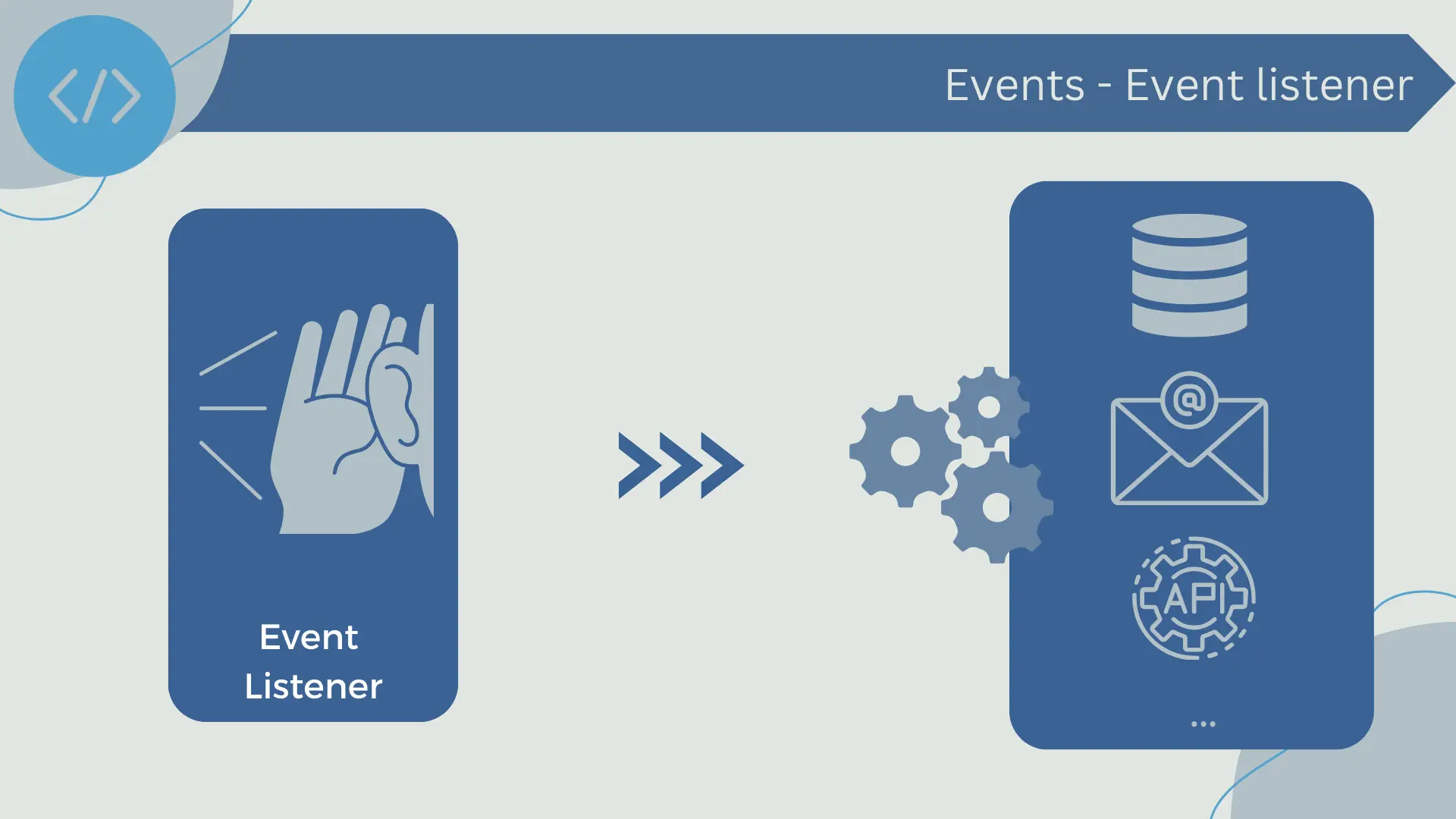
Event Receivers
Event receivers are components or actors in an event-driven system that listen to and react to events. These components are subscribed to one or more types of events on the event bus. When an event arrives that they are subscribed to, they perform an action or a series of actions.
Each event receiver is designed to handle a specific task or set of tasks. For example, in an e-commerce system, there might be an event receiver listening to "new order" events and updating the inventory database accordingly. Another event receiver might be listening to the same "new order" events, and its task could be generating invoices.
The implementation of event receivers varies depending on the nature of the tasks they need to perform. Some event receivers might be simple functions or methods in an application, while others might be complete services with their own database and other resources.
In terms of organization, event receivers are typically organized according to the needs of the business. Receivers handling related tasks can be grouped together in a module or service.
Similar to event emitters, event receivers are decoupled from the rest of the system. This means they can be added, modified, or removed without affecting the rest of the system, providing flexibility and facilitating scalability and evolution of the system. Additionally, since event receivers act in response to events, this model allows the system to be reactive and efficiently handle different types of events.
Request Handling
In an event-driven architecture, request handling is not as straightforward as in other architectural models due to its inherently asynchronous and decoupled nature. Instead of directly requesting and receiving responses, components in the system emit events that other components handle independently. Let's take a closer look at how requests are handled in this architecture.
Event Generation
Event generation is the initial process in an event-driven architecture. An event is generated when an action or change occurs in the system that needs to be communicated to other components. Events can be generated by a wide variety of sources, including user actions, sensor signals, data changes, or even time-based events like timer expiration.
Each event consists of a set of data representing the action or change that has occurred. For example, if the event is the result of a user action, the event data could include details about the action performed, such as the type of action, the user who performed it, and any associated data with the action.
In most cases, events are immutable, meaning that once an event has been generated, it cannot be modified. Instead of modifying an existing event, a new event would be generated to represent any additional changes.
It's important to note that event generation is an asynchronous process. This means the event emitter does not expect an immediate response or even any response at all after emitting an event. Instead, the event emitter simply emits the event and continues with its processing, while other components in the system handle the event independently and in their own time. This asynchronous nature is one of the key characteristics of event-driven architectures, enabling them to efficiently handle concurrent and scalable operations.
Event Dispatching
Once an event is generated, the next step is to dispatch it across the system. The process of sending an event from its source (the emitter) to its recipients (the receivers) is done through the event bus.
The event bus is a messaging system that provides the necessary means to transmit events across the system's architecture. Event transmission happens asynchronously, meaning that events are emitted and received independently of the main control flow of the system.
The event bus must be capable of handling a high volume of events simultaneously and ensure that each event reaches its intended destination reliably. Techniques such as replication and fault tolerance are often implemented to achieve this.
It's important to highlight that event dispatching in an event-driven architecture is a one-way process. Unlike requests in request-response architectures, where the response is sent back to the requester, in an event-driven architecture, events are emitted without expecting a direct response.
How events are transmitted and managed by the event bus has a significant impact on the performance and scalability of the system. For example, if the event bus is capable of quickly transmitting events and handling a high volume of events, it can enable the system to handle heavy workloads and respond quickly to changes. On the other hand, if the event bus is slow or unable to handle a large volume of events, it can limit the system's ability to handle heavy workloads and respond quickly to changes.
Event Reception and Processing
Event reception is the process by which a component in the system (receiver) receives an event from the event bus. Event processing refers to the set of actions performed after the event has been received.
Receiver components are designed to listen and react to certain types of events. When an event arrives at the receiver, it can perform various actions such as updating its state, storing data, or emitting new events. These actions depend on the nature of the event and the business logic implemented in the receiver.
It's important to note that event processing is asynchronous and, in many cases, parallel. This means that different events can be processed by different components in the system at the same time, allowing for high concurrency and efficiency.
However, asynchronous event processing can also lead to race conditions and consistency issues. To handle these problems, strategies such as event ordering, delivery guarantees, and compensation mechanisms are often implemented.
The scalability and efficiency of event processing heavily depend on the system's ability to handle multiple events simultaneously and each component's ability to process events efficiently. If the system can handle a large number of events simultaneously, and each component can process events quickly, it can enable the system to handle heavy workloads and respond quickly to changes.
Asynchronous Responses
In an event-driven architecture, unlike request-response architectures, responses to events are typically asynchronous. This means that when a component emits an event, it does not expect an immediate response from the event receiver.
Instead of receiving a direct response to an event, the emitter can listen for other events that indicate the outcome of its original action. For example, after emitting an event requesting a change in data, the emitter can listen for an event indicating that the data has been successfully changed.
Let's imagine a store that manages an order system that connects with a transportation company's delivery control API. The store generates an order, and when it's ready, it emits an event to be listened to by the delivery company's API for pickup. Once the company delivers the order to the end customer, it emits an event to notify the store that it has reached its destination, allowing the store to update the order status as Delivered.
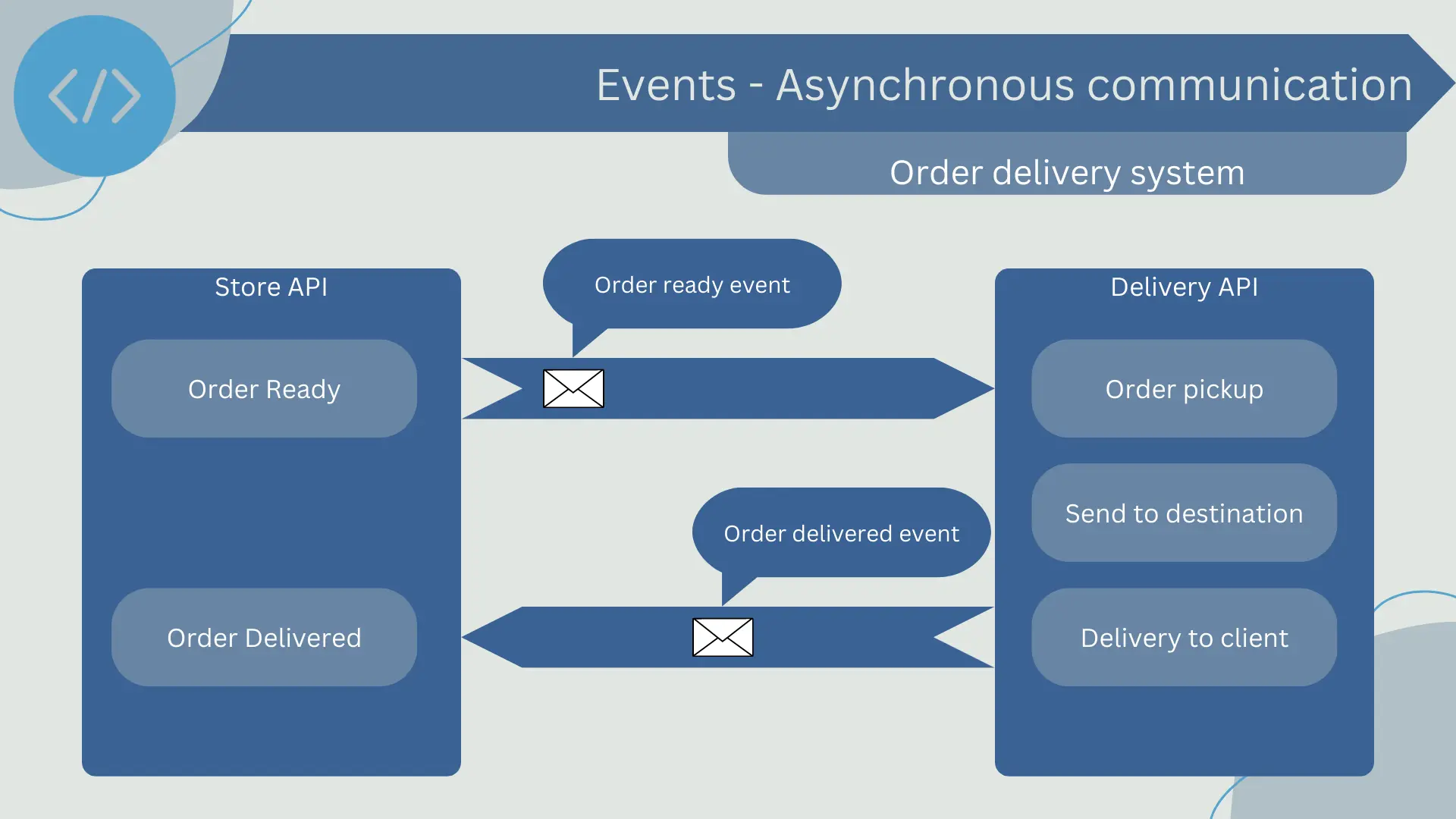
Asynchronous responses allow for a high degree of decoupling between components in the system. Since components do not need to wait for responses to their events, they can continue processing other events and performing other tasks. This decoupling also allows components in the system to fail and recover independently, enhancing the system's resilience.
However, managing asynchronous responses can be complex. Systems must be prepared to handle situations where responses to events may not arrive, arrive late, or arrive in a different order than expected. Common strategies for handling these situations include using timers, implementing retry logic, and building request tracking systems.
Event Persistence
In an event-driven architecture, event persistence is a critical aspect for maintaining system integrity, facilitating fault recovery, and providing a source of truth for the system's state.
Events in an event-driven system represent significant state changes that occur within the system. When these events are persisted, an immutable record of all the changes that have occurred in the system is created. This record can be used for various purposes, including:
- Fault recovery: If a component of the system fails, persisted events can be used to reconstruct the component's state before the failure.
- Diagnostics and troubleshooting: Persisted events provide a detailed history of what has occurred in the system, which can be invaluable for identifying and resolving issues.
- Auditing and compliance: In many cases, a detailed record of actions and changes in the system needs to be maintained to meet auditing and compliance requirements.
- Event sourcing: Event persistence enables the Event Sourcing design pattern, where the current state of the system can be reconstructed by replaying the sequence of events from the beginning.
Event persistence can be achieved in a variety of ways, depending on the system's needs. Some systems may persist events in a relational database, while others may use a NoSQL database or a storage system specifically designed for event persistence.
It's important to note that event persistence can introduce additional challenges, such as the need to manage large volumes of data and ensure data consistency and integrity. Additionally, event persistence can have implications in terms of privacy and security, as events often contain sensitive information.
Scalability
Event-driven architecture has inherent advantages that favor scalability. By functioning asynchronously and in a distributed manner, it has the potential to handle large volumes of traffic and activity without degrading performance. Several key subtopics related to the scalability of this architecture are developed here.
Parallel and Concurrent Processing
In an event-driven architecture, each event can be considered as an independent unit of work. This means that different events can be processed simultaneously, allowing for the utilization of multiple cores or CPUs available in the system or even distributing the work across different machines.
- Parallelism: Refers to the ability to execute multiple tasks simultaneously. In the context of event-driven systems, this means that multiple events can be processed at the same time as long as sufficient resources are available (e.g., CPU cores or machines in a network).
- Concurrency: In computing, concurrency is the ability of a system to handle multiple tasks at the same time, but not necessarily simultaneously. In a concurrent system, tasks are processed in a way that appears to be happening at the same time, but they may actually be sharing a single resource (such as a CPU core) by quickly alternating between them.
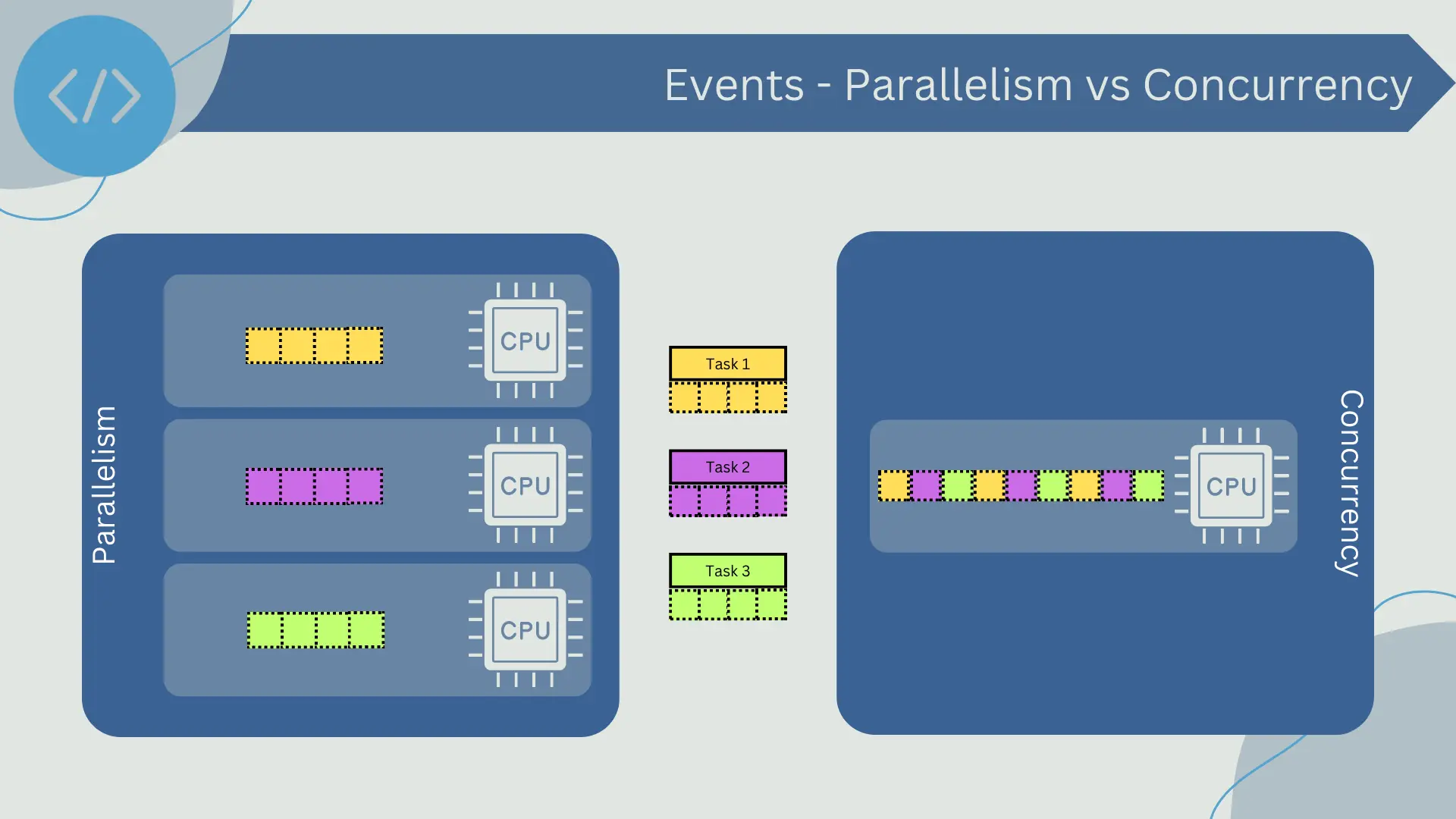
The ability to process events in parallel and concurrently is one of the factors that contribute to the high scalability of event-driven systems. However, parallel and concurrent processing also introduces several challenges. One of them is the need to synchronize access to shared resources to avoid race conditions. Another challenge is ensuring proper event ordering when necessary, as parallel processing can lead to events being processed out of order.
Elasticity
Elasticity is one of the key advantages of event-driven architecture and is fundamental to its scalability. It refers to a system's ability to dynamically adjust the resources it utilizes in response to variations in demand.
In the context of an event-driven architecture, this means that the system can adapt to an increasing volume of events by adding more event consumers, also known as workers, to process incoming events. Similarly, when the volume of events decreases, the system can release resources that are no longer needed by removing additional event consumers.
This dynamic resource adjustment can be done manually by system operators, but it can also be automated using orchestration and monitoring systems that can adjust resources based on performance metrics and system utilization.
Elasticity is essential for maintaining high availability and performance in the system, as it enables the system to handle load spikes without degrading performance. At the same time, the ability to release resources when they are not needed helps keep operational costs under control.
It's important to note that while elasticity allows for adapting to load variations, it also introduces additional complexity in system management as it requires constant monitoring and may require sophisticated orchestration systems to efficiently adjust resources. Additionally, the dynamic addition and removal of resources can have implications for system coherence and stability, which need to be carefully managed.
Decoupling
Decoupling is a key concept in event-driven architecture and plays an essential role in its scalability. Decoupling refers to reducing direct dependencies between different components of a system, allowing each component to evolve, scale, and fail independently.
In event-driven architecture, decoupling is primarily achieved through the use of events as a means of communication between components. Each component in the system interacts with others by emitting or consuming events, rather than directly calling other components' interfaces. This means that components do not need to have direct knowledge of each other, and they can scale, evolve, and fail independently as long as they comply with the contract established by the events they emit or consume.
Decoupling facilitates scalability by allowing each component in the system to scale independently in response to load. For example, if a component is experiencing a high load, more instances of that component can be added to handle the load without affecting other components in the system.
Additionally, decoupling also increases the resilience of the system as it allows the system to continue functioning despite the failure of one or more components. For example, if a component fails, the events it emits can be queued until the component is restored, without affecting other components that consume these events.
However, decoupling also introduces complexity into the system as it requires careful handling of events and can lead to situations where tracking and understanding interactions between components becomes challenging. For this reason, it's important to combine decoupling with good tracking and monitoring practices to maintain visibility and understanding of the system.
Scalability Challenges
Event-driven architecture, although powerful and flexible, also presents several challenges when it comes to scalability. Some of the key challenges include:
- Event and message design: Designing events and messages that are generic enough to be reused by multiple consumers but also specific enough to provide value can be challenging. This can be especially difficult as the system grows and evolves over time.
- Event processing in order: Ensuring that events are processed in the correct order can be challenging, especially in highly concurrent systems where events may be processed by multiple consumers in parallel. Strategies such as event ordering, event-to-consumer mapping, or using design patterns like event sequencer can help, but they can also increase system complexity.
- Eventual consistency: In an event-driven architecture, eventual consistency is often chosen over immediate consistency. This can lead to situations where data is temporarily in an inconsistent state. Designing a system that can handle these states correctly and ensure eventual consistency can be a challenge.
- Monitoring and debugging: In an event-driven system, operations can become more difficult to trace as there are no direct service calls but rather a series of events that can be consumed by one or more services. This can make problem identification and understanding of data flow more challenging.
- Load spikes: Event-driven systems can experience load spikes when a large number of events occur within a short period. These spikes can overload event consumers and cause performance issues or failures. Designing a system that can efficiently handle these load spikes can be a challenge.
Each of these challenges requires careful consideration and often domain-specific solutions. In some cases, these challenges may require trade-offs between the benefits and drawbacks of event-driven architecture.
Development and Lifecycle
The development and lifecycle of an event-driven architecture have distinctive characteristics due to its asynchronous and highly decoupled nature. This model can significantly influence how systems are designed, implemented, tested, deployed, and maintained. Several key aspects of development and lifecycle in event-driven architecture are described below.
- Event and contract design: System design often begins with defining events and their contracts, which include the data associated with each event type. This establishes the foundation for interaction between system components. A good practice is to make event contracts as independent as possible from the programming language and to use open standards like JSON or Protobuf.
- Implementation: Each system component is implemented to produce, consume, or react to the defined events. These components can be implemented in different programming languages and technologies, thanks to the decoupling provided by event-driven architecture.
- Testing: Testing in an event-driven architecture can be more challenging due to its asynchronous nature. Unit and integration testing often require the use of mocks and stubs for event producers and consumers. End-to-end testing and load testing are crucial to ensure the system behaves correctly under production conditions.
- Deployment: Deployment in an event-driven architecture often utilizes containers and orchestrators like Kubernetes to handle distribution, scalability, and fault recovery. DevOps and CI/CD practices are essential for efficient deployment and management.
- Monitoring and debugging: Given the distributed and asynchronous nature of event-driven architectures, monitoring and debugging can be challenging. Distributed tracing tools, log aggregation, and performance monitoring systems can be helpful in gaining real-time insights into the system and investigating issues.
- System evolution: Since components are decoupled, they can be added, modified, or removed without impacting the rest of the system. However, changes to event contracts must be carefully handled to avoid compatibility issues.
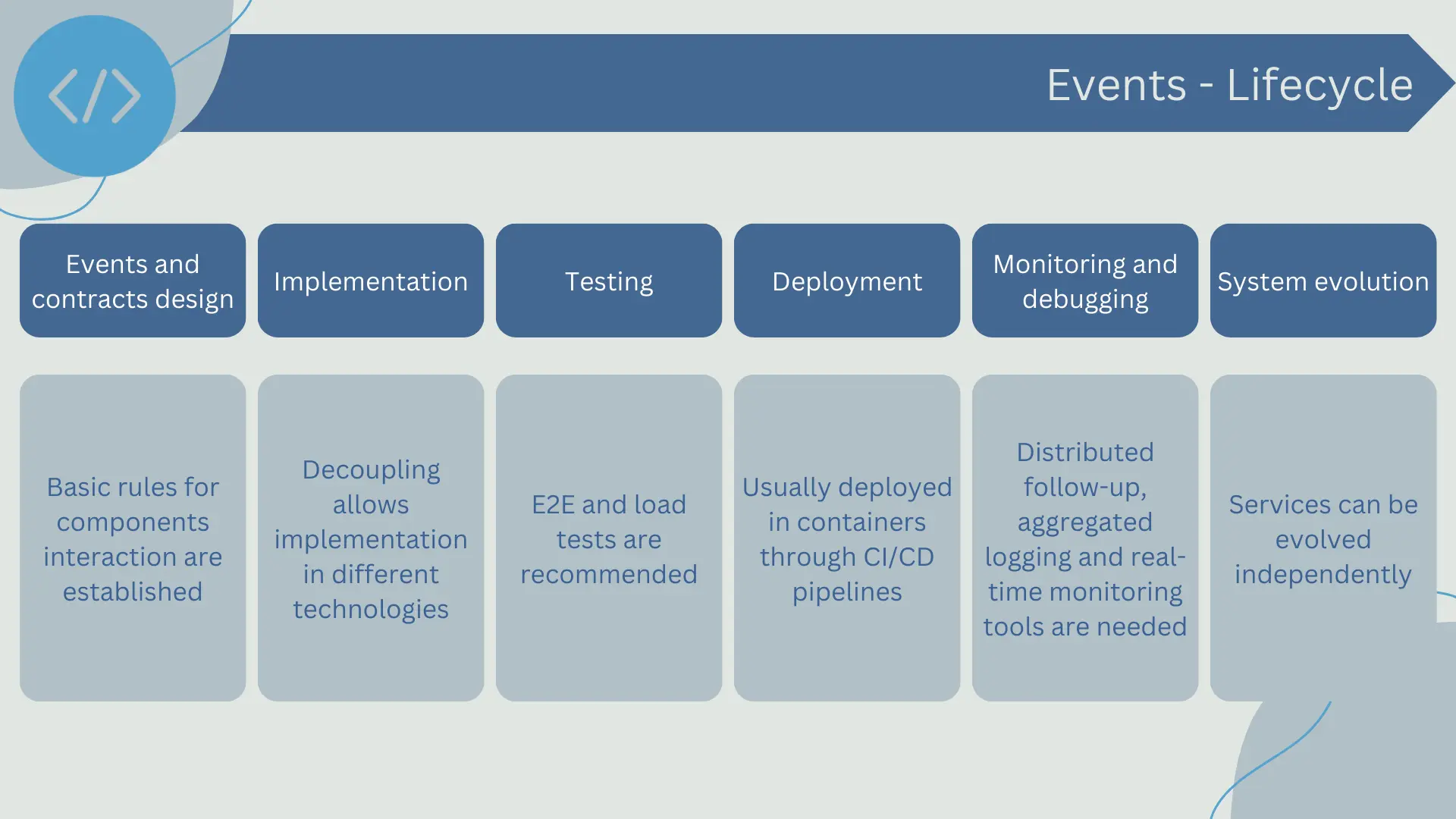
In summary, event-driven architecture has a distinct development lifecycle that can influence the practices and tools used. Like any architectural approach, it is essential to understand these differences and adapt development practices to make the most of the advantages offered by event-driven architecture.
Use Cases
Event-driven architecture is particularly useful in situations where high scalability, responsiveness, and decoupling among system components are needed. Let's look at some examples of use cases that particularly benefit from this architectural model.
- Real-time transaction processing systems: In e-commerce, finance, and other domains, there is often a need to process high volumes of real-time transactions. An event-driven architecture is an excellent choice for such systems as it enables handling load spikes, provides a high degree of decoupling, and facilitates concurrent transaction processing.
- Internet of Things (IoT) systems: IoT systems typically involve a large number of devices generating events, such as sensor readings, that need to be processed and responded to in real-time. Event-driven architecture is ideal for handling the scale and asynchronous nature of such interactions.
- Data stream analysis applications: Applications that need to analyze and respond to real-time data streams, such as monitoring and alerting applications, greatly benefit from an event-driven architecture. This includes log analysis applications, system performance monitoring, fraud detection, among others.
- Messaging and notification systems: Systems that handle messaging and notifications often need to efficiently, scalably, and in real-time process a large volume of events. Chat systems, social media platforms, and incident notification systems are examples of such applications.
- Microservices and distributed systems: In general, any system that benefits from decomposition into smaller, decoupled components can benefit from an event-driven architecture. This architecture is often a fundamental part of designing microservice-based systems, where different services primarily interact through events.
These are just a few examples. In general, any system that needs to handle a high volume of events, requires realtime event processing, or benefits from a high degree of decoupling among its components is a good candidate for an event-driven architecture. However, it's important to remember that, like any architecture, it should be chosen based on the specific needs and requirements of the system.