Los conectores son los mecanismos que permiten la interacción y colaboración entre los diferentes componentes de software. Son responsables de la transmisión de datos y control entre componentes, lo que resulta esencial para lograr una arquitectura de software cohesiva y eficiente. Los conectores también pueden encargarse de aspectos como la transformación de datos y la coordinación del control, especialmente en sistemas más complejos.
Existen diferentes tipos de conectores, cada uno con características y propósitos específicos. Algunos de los conectores más comunes incluyen:
- Llamadas a Procedimientos: Este es probablemente el tipo de conector más común y se usa cuando un componente necesita invocar la funcionalidad de otro componente.
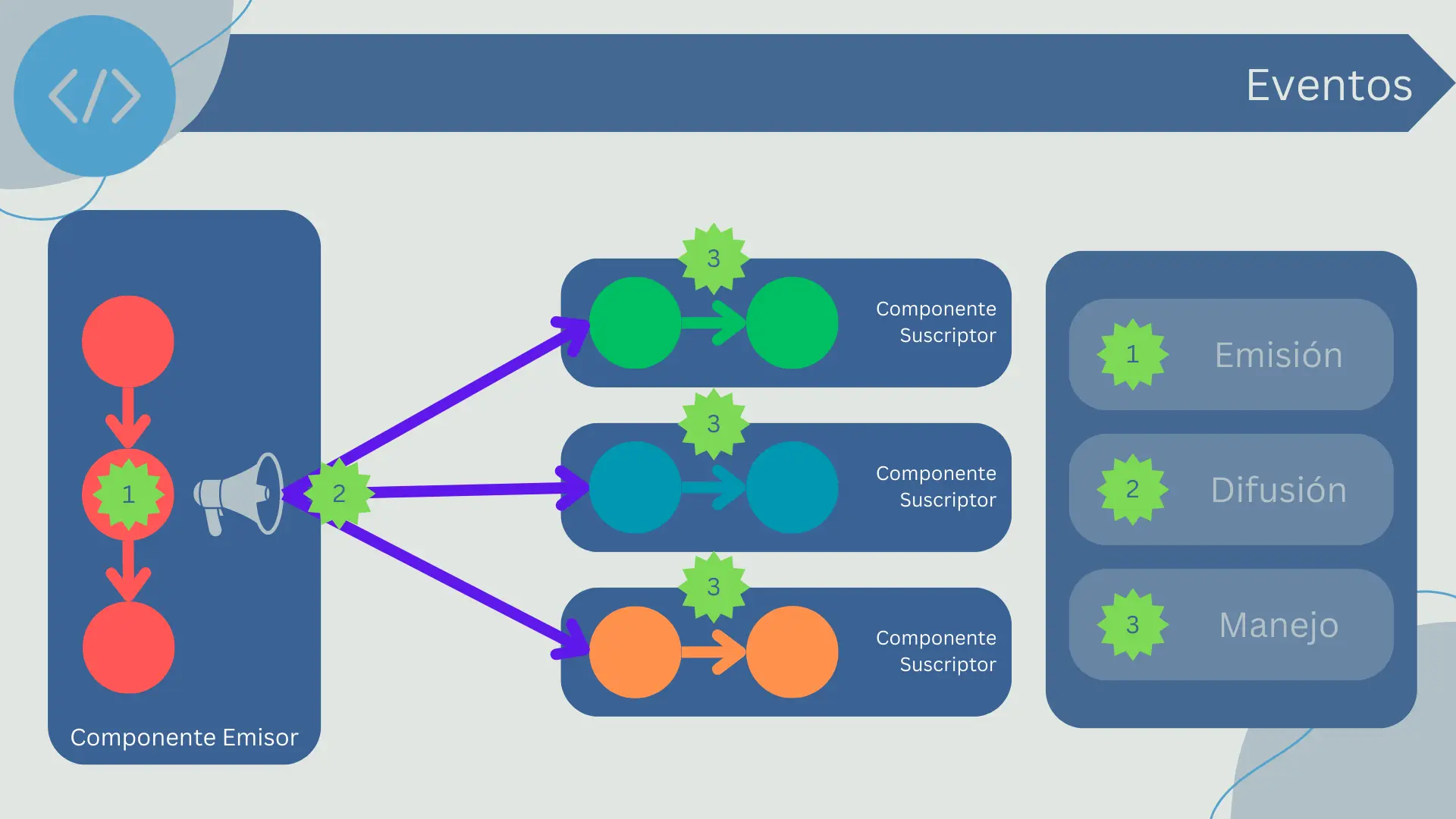
- Eventos: En sistemas basados en eventos, un componente (el emisor) genera un evento que uno o más componentes (los receptores) pueden capturar y responder. Este tipo de conectores es esencial en las arquitecturas orientadas a eventos.
- Bases de Datos Compartidas: Este conector se usa cuando dos o más componentes necesitan compartir información a través de una base de datos común.
- Colas de Mensajes: En sistemas distribuidos, las colas de mensajes son utilizadas para permitir que los componentes se comuniquen de manera asincrónica.
- Servicios Web o APIs REST: En arquitecturas basadas en microservicios, las APIs REST son comúnmente usadas como conectores entre los diferentes microservicios.
Es crucial elegir el tipo correcto de conectores para garantizar que los componentes de software se comuniquen y colaboren de manera eficiente. La elección del conector depende de varios factores, como los requisitos de rendimiento, seguridad, escalabilidad, y las características específicas del sistema y su entorno de ejecución. Por lo tanto, al diseñar la arquitectura de software, se debe prestar especial atención a la elección y diseño de los conectores.
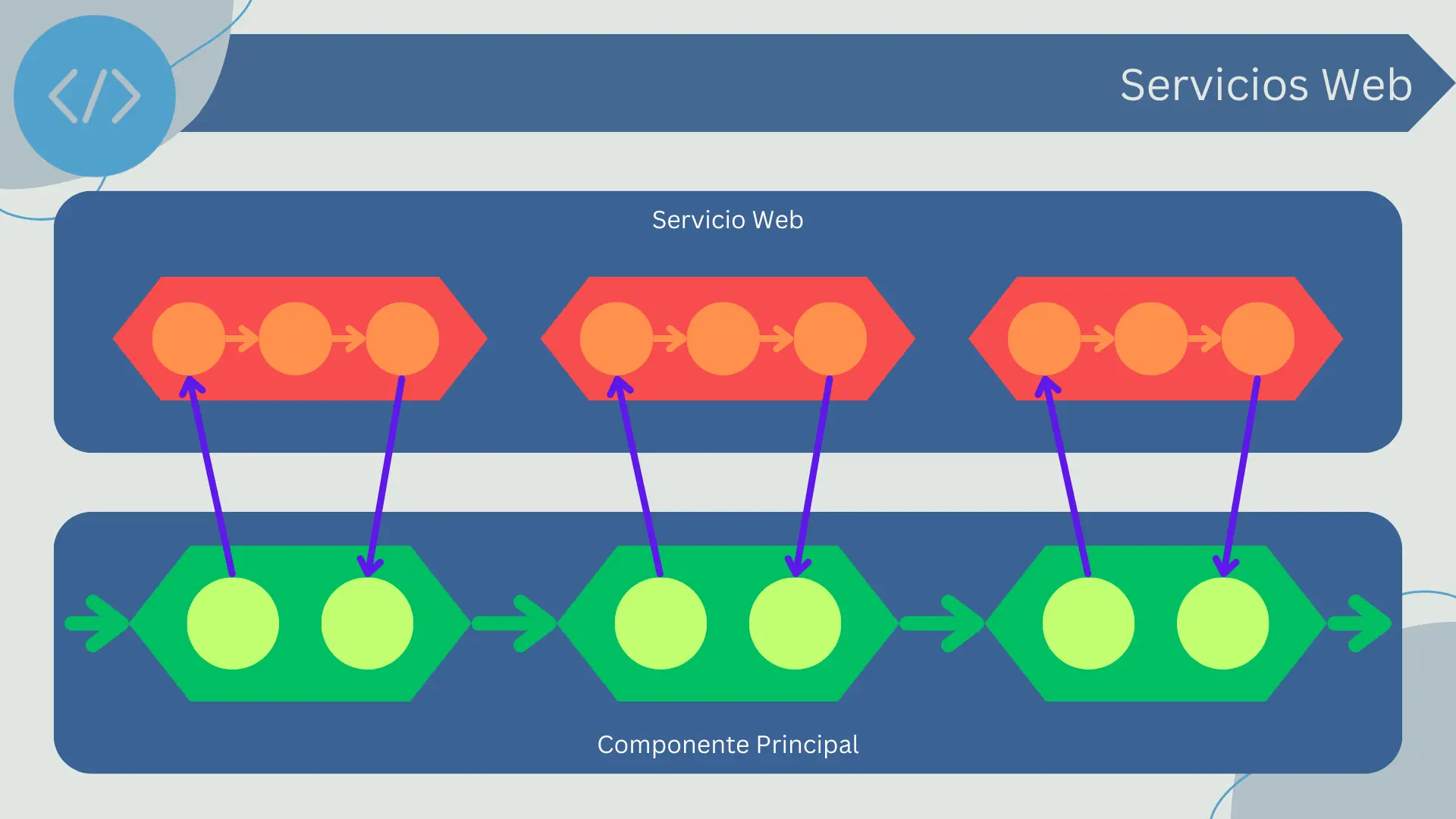
Llamadas a Procedimientos
Las llamadas a procedimientos son una forma común de interacción entre componentes de software. Cuando se emplea este tipo de conector, un componente (el llamante) ejecuta una función o método que pertenece a otro componente (el llamado).
La llamada a procedimientos es un mecanismo de conexión síncrono, lo que significa que el componente llamante se bloquea y espera hasta que el procedimiento llamado haya finalizado su ejecución y devuelto el control. Este estilo de interacción es común en muchas arquitecturas de software y es particularmente predominante en la programación orientada a objetos.
Una llamada a procedimiento generalmente consiste en:
- Invocación: El componente llamante invoca a un procedimiento del componente llamado, pasándole argumentos si es necesario.
- Ejecución: El componente llamado ejecuta el procedimiento, que puede involucrar la realización de cálculos, la manipulación de datos o la invocación de otros procedimientos.
- Retorno: Una vez que el procedimiento ha terminado de ejecutarse, el control se devuelve al componente llamante. Si el procedimiento está diseñado para devolver un valor, este valor se pasa al llamante en el momento del retorno.
Las llamadas a procedimientos son un método de conexión muy directo y eficiente. Permiten una fuerte cohesión entre componentes y proporcionan una forma sencilla y directa de compartir datos y funcionalidad. Sin embargo, también pueden resultar en un acoplamiento fuerte entre los componentes, lo que puede reducir la modularidad y la flexibilidad del sistema. En particular, el uso de llamadas a procedimientos síncronas puede llevar a bloqueos y a una menor reactividad si no se manejan correctamente.
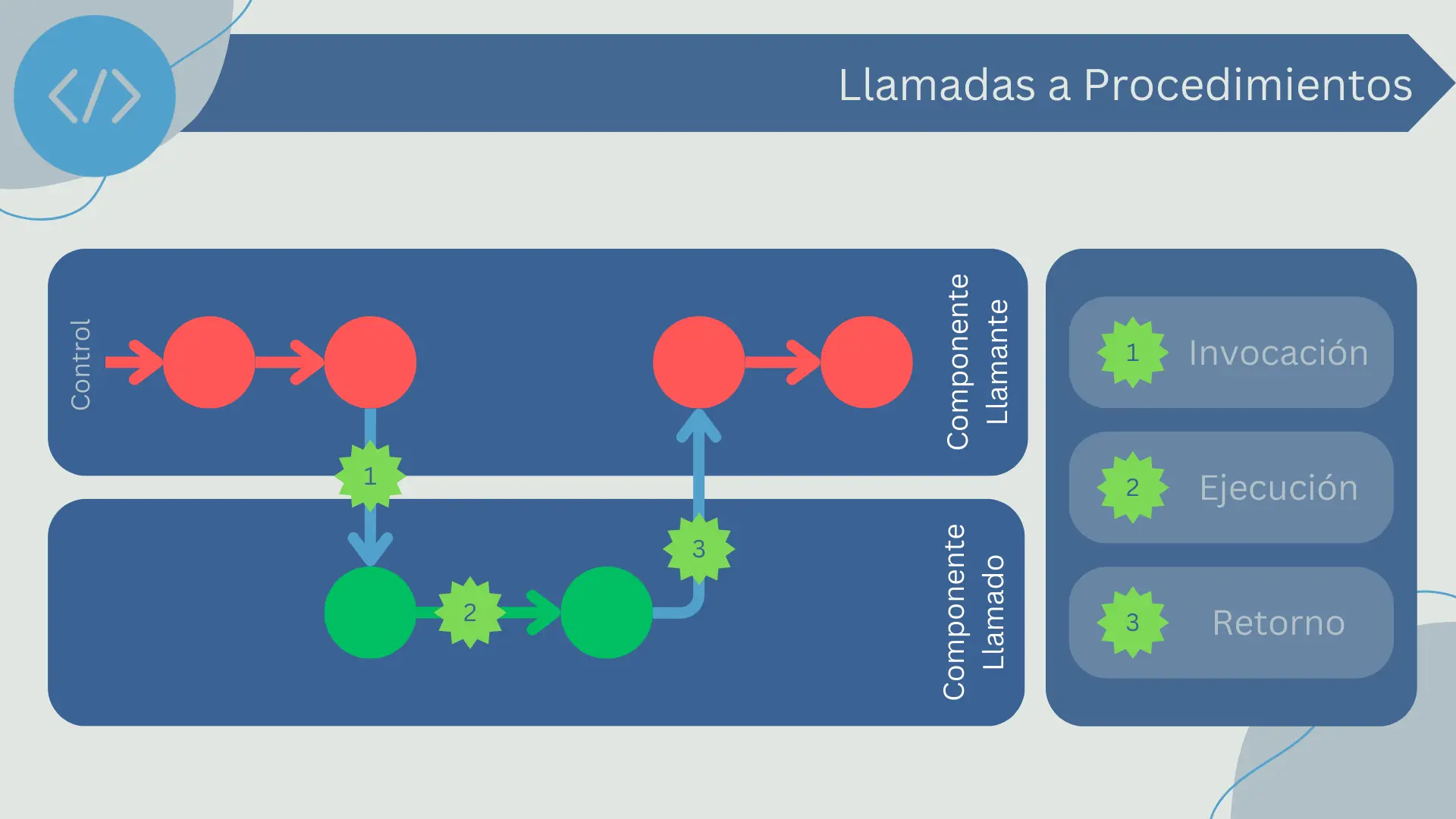
Eventos
Los eventos son otra forma común de interacción entre componentes de software. En un modelo basado en eventos, un componente (el emisor) genera un evento que representa una cierta condición o cambio de estado. Otros componentes (los oyentes o suscriptores) pueden estar interesados en ese evento y reaccionar a él.
Los eventos son un mecanismo de conexión asincrónico, lo que significa que el emisor no se bloquea y no espera a que los oyentes respondan. En lugar de ello, simplemente emite el evento y luego continúa con su propia ejecución. Los oyentes que están interesados en el evento lo procesarán cuando puedan.
Un evento generalmente consta de:
- Emisión: El emisor genera un evento, posiblemente incluyendo algunos datos relacionados con el evento.
- Difusión: El evento es transmitido a todos los oyentes interesados. Esto puede hacerse a través de un "bus de eventos" que gestiona la entrega de eventos, o los oyentes pueden registrarse directamente con el emisor para recibir sus eventos.
- Manejo: Cada oyente recibe el evento y decide qué hacer con él. Esto puede implicar la ejecución de algún código en respuesta al evento, la actualización de su estado interno, la emisión de sus propios eventos, o cualquier combinación de los anteriores.
Los eventos son una forma poderosa y flexible de conectar componentes. Permiten un acoplamiento suelto entre el emisor y los oyentes, lo que puede aumentar la modularidad y la reusabilidad del sistema. Los eventos también permiten un estilo de programación reactiva, en la que los componentes responden a los cambios en lugar de seguir un flujo de control predeterminado.
Sin embargo, los sistemas basados en eventos pueden ser más difíciles de entender y depurar que los que utilizan llamadas a procedimientos, ya que el flujo de control no es lineal y puede ser difícil rastrear cómo y cuándo se manejan los eventos. También pueden surgir problemas si los eventos se pierden, se entregan fuera de orden o se manejan de manera inconsistente.
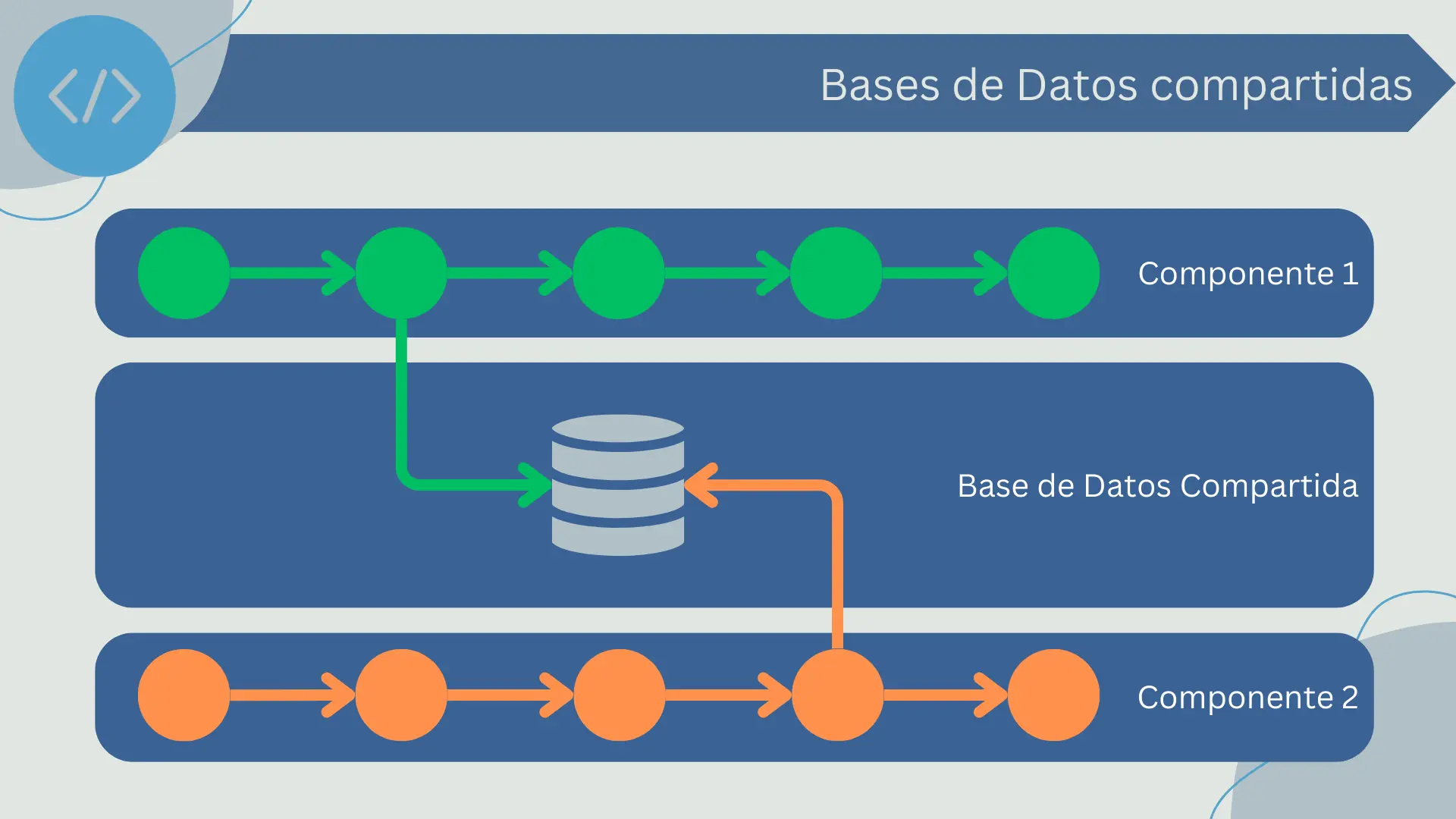
Bases de Datos Compartidas
Una base de datos compartida es una forma de conexión en la que dos o más componentes de software interactúan compartiendo el mismo conjunto de datos, en lugar de hacerlo a través de llamadas a procedimientos o eventos. La base de datos actúa como un repositorio común que cualquier componente puede leer o escribir.
Por ejemplo, un componente puede ser responsable de actualizar ciertos datos en la base de datos, mientras que otros componentes pueden leer esos datos para llevar a cabo su propia lógica de negocio. Este es un enfoque común en las arquitecturas de software empresarial, donde los diferentes componentes a menudo necesitan acceder y manipular los mismos datos.
Una de las principales ventajas de este enfoque es que puede simplificar el intercambio de datos entre componentes, ya que todos pueden leer y escribir en la misma base de datos. También puede proporcionar una forma consistente y confiable de gestionar los datos, especialmente si la base de datos tiene características como transacciones y bloqueo para garantizar la coherencia y evitar las condiciones de carrera.
No obstante, compartir una base de datos también puede llevar a problemas. Puede llevar a un acoplamiento estrecho entre los componentes, ya que todos dependen de la misma base de datos y posiblemente del mismo esquema de base de datos. Esto puede hacer que sea más difícil cambiar o evolucionar el esquema de la base de datos, ya que cualquier cambio podría afectar a todos los componentes que la utilizan.
Además, puede surgir la competencia por los recursos de la base de datos, lo que puede afectar al rendimiento del sistema. Y si la base de datos se cae, todos los componentes que dependen de ella también pueden verse afectados.
Debido a estos problemas, las bases de datos compartidas se suelen utilizar con precaución y se combinan con otras formas de conexión, como las llamadas a procedimientos y los eventos. En particular, las arquitecturas modernas como los microservicios a menudo evitan compartir bases de datos entre diferentes servicios, y en su lugar favorecen enfoques como las API y los eventos para el intercambio de datos.
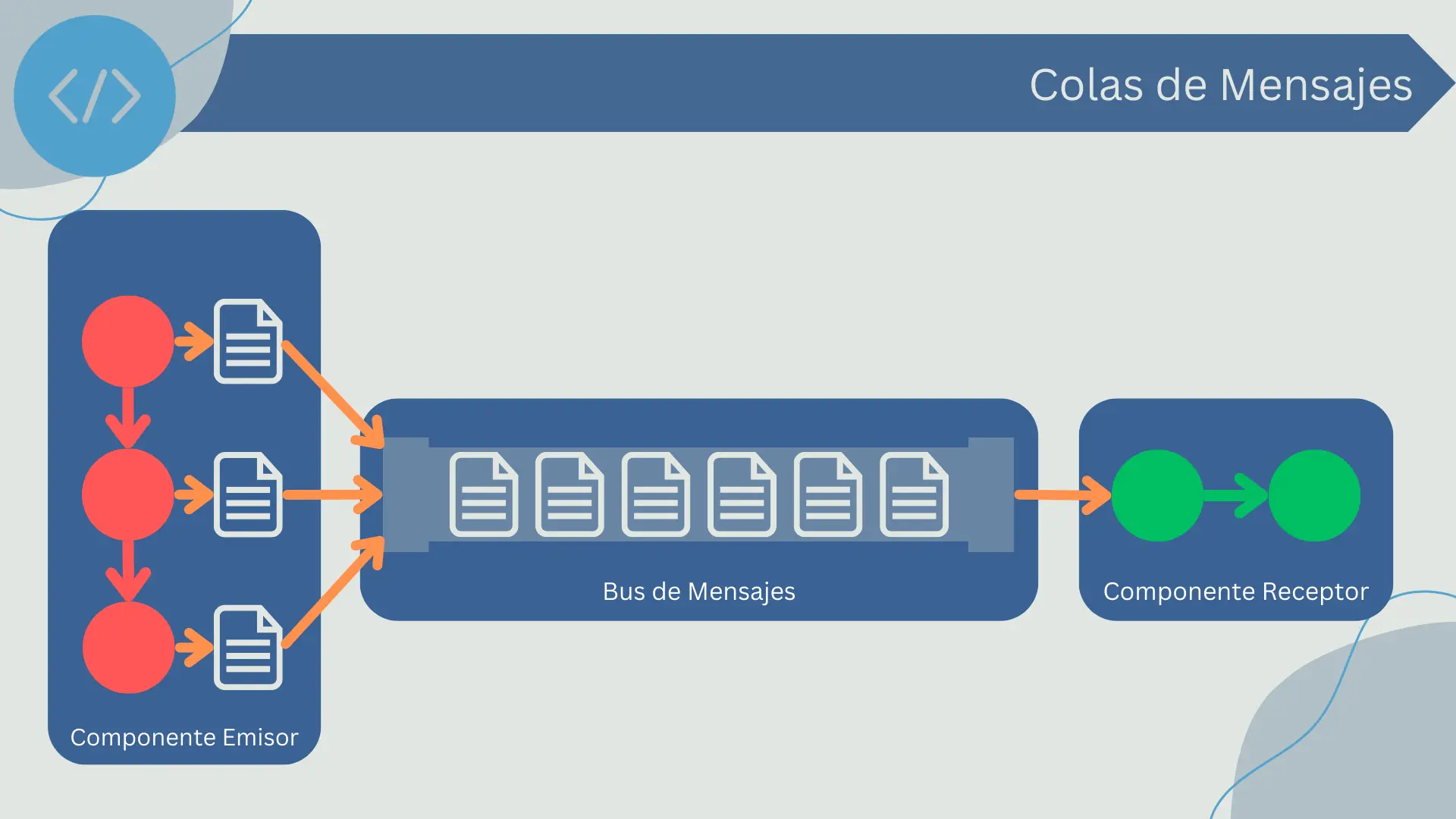
Colas de Mensajes
Las colas de mensajes son un método de conexión entre componentes de software que utiliza una cola para almacenar los mensajes que deben ser procesados. En lugar de enviar un mensaje directamente de un componente a otro, el emisor coloca el mensaje en una cola y el receptor lo extrae de la cola para procesarlo.
Las colas de mensajes proporcionan un acoplamiento débil entre los componentes y permiten una comunicación asíncrona. Esto significa que el emisor y el receptor no necesitan estar activos al mismo tiempo para que el mensaje se transmita. Además, las colas de mensajes pueden ayudar a gestionar la carga en sistemas de alto tráfico, ya que permiten a los mensajes acumularse en la cola para ser procesados cuando el sistema tiene capacidad para hacerlo.
La ventaja principal de las colas de mensajes es que permiten un acoplamiento débil y una comunicación asíncrona. Esto puede hacer que el sistema sea más escalable y resistente, ya que los componentes pueden seguir funcionando incluso si otros componentes están caídos o ocupados. Además, las colas de mensajes pueden ayudar a gestionar la carga y a evitar que el sistema se sobrecargue en momentos de alto tráfico.
Sin embargo, las colas de mensajes también tienen sus desventajas. Por un lado, pueden introducir latencia adicional, ya que los mensajes deben ser colocados en la cola y luego extraídos de ella. Además, si un componente coloca un gran número de mensajes en la cola, puede llenarse y provocar la pérdida de mensajes. También puede ser más difícil seguir el flujo de la lógica de la aplicación, ya que los mensajes se procesan de forma asíncrona.
Además, el uso de colas de mensajes puede requerir una infraestructura adicional, como un servidor de colas de mensajes, y puede complicar la gestión de errores, ya que los errores pueden ocurrir en cualquier punto de la cadena de mensajes.
Servicios Web o APIs REST
Las APIs REST (Representational State Transfer) son un tipo de servicios web que proporcionan una interfaz para interactuar con un servidor web utilizando el protocolo HTTP. Los servicios web RESTful están construidos alrededor de los métodos estándar de HTTP como GET, POST, PUT y DELETE para realizar operaciones en los recursos.
Un recurso en un servicio web RESTful es una abstracción de una entidad en el sistema que se está diseñando. Cada recurso es identificado de manera única por un URI (Uniform Resource Identifier). La ventaja clave de los servicios web RESTful es su simplicidad. Al usar el protocolo HTTP, se integran fácilmente con la infraestructura de Internet existente.
Las APIs REST ofrecen varias ventajas. Son simples de usar y comprender, ya que utilizan métodos HTTP estándar. Al ser sin estado, permiten que las solicitudes se procesen independientemente unas de otras, lo que puede facilitar la escalabilidad. Además, se pueden usar para conectar componentes de software que se ejecutan en diferentes lenguajes de programación o en diferentes plataformas.
Por otro lado, las APIs REST también tienen algunas desventajas. Una de las más importantes es que son sincrónicas, lo que significa que el cliente debe esperar una respuesta antes de continuar. Esto puede ser un problema si las solicitudes son lentas o si el servidor está sobrecargado. Además, al ser basadas en texto (normalmente en formato JSON), pueden ser menos eficientes que otras opciones para la transmisión de grandes volúmenes de datos o datos binarios.
En general, las APIs REST son una opción popular para conectar componentes de software en la web debido a su simplicidad y su capacidad para integrarse con la infraestructura existente de Internet.